特集記事¶
ストーリー仕立ての横断的実用記事。リファレンス章を横断して、特定のユースケースを最初から最後まで解説します。
他章との関係: - 08-config-procedures / 09-incident-procedures は手順カタログ - 本章 (11-special-features) はストーリー記事(長い、横断的、シナリオ仕立て)
v8 投入記事一覧:
| ID | タイトル | 重要度 | カテゴリ | 概要 |
|---|---|---|---|---|
| feature-01-disk-to-fs | ディスク容量確認から新規ファイルシステム作成まで | S |
ストレージFS | ユーザから「データ置き場が欲しい」と依頼を受けて、既存容量を確認し、必要なら新規 PV を組み込んで LV/FS を作成、運用に引き渡すまでの一気通貫手順。 |
| feature-02-perf-investigation | 性能ボトルネック調査から改善・効果測定まで | S |
性能 | 「業務系の応答が遅い」というクレームを受けて、CPU/メモリ/ディスク/ネットワークから真因を特定し、tunable や構成変更で改善、効果を定量測定して報告するまで。 |
| feature-03-patch-apply | パッチ適用前準備から適用・検証・rollback まで | S |
パッケージ | セキュリティ TL/SP 適用の標準手順。事前バックアップ → 適用 → 動作検証 → 失敗時の rollback まで。本番環境で安全に進めるためのチェックポイントを網羅。 |
| feature-04-bulk-user-mgmt | ユーザ大量追加とグループ設計・監査ログ有効化 | S |
ユーザ認証 | 新部署発足や M&A による 50 ユーザ一括追加。グループ設計、共通ポリシー適用、監査ログ有効化、定期棚卸しの仕組み構築まで。 |
| feature-05-tcpip-change | TCP/IP 設定変更から検証・運用反映まで | S |
ネットワーク | ネットワークセグメント変更(VLAN 移動・IP 帯変更)の本番系作業。事前準備から ifconfig 変更、ルーティング、DNS 更新、関連サーバ通知、業務確認まで。 |
本章の品質方針
全特集記事は IBM AIX 7.3 公式マニュアル記載の事実・手順のみ で構成しています。AI が苦手な定性的判断は範囲外として、各記事末尾に「本記事の範囲」として明示しています。
特集 1: ディスク容量確認から新規ファイルシステム作成まで¶
重要度: S / カテゴリ: ストレージFS
概要: ユーザから「データ置き場が欲しい」と依頼を受けて、既存容量を確認し、必要なら新規 PV を組み込んで LV/FS を作成、運用に引き渡すまでの一気通貫手順。
シナリオ¶
開発チームから依頼:
新しいアプリのログ・データ置き場として /data に 20GB の領域がほしい。 既存 FS(/var など)と容量を取り合いたくないので、専用領域として確保してください。
この特集記事は、依頼を受けた AIX 管理者が 「既存容量を確認 → 不足判断 → 新規 PV 認識 → VG 拡張 → LV 作成 → FS 作成 → マウント → 運用引き継ぎ」 までを一気に進める実例です。
途中で「既存 VG に空きあり / なし」「新規 VG が必要 / 不要」の分岐があるので、判断ポイントも明示します。
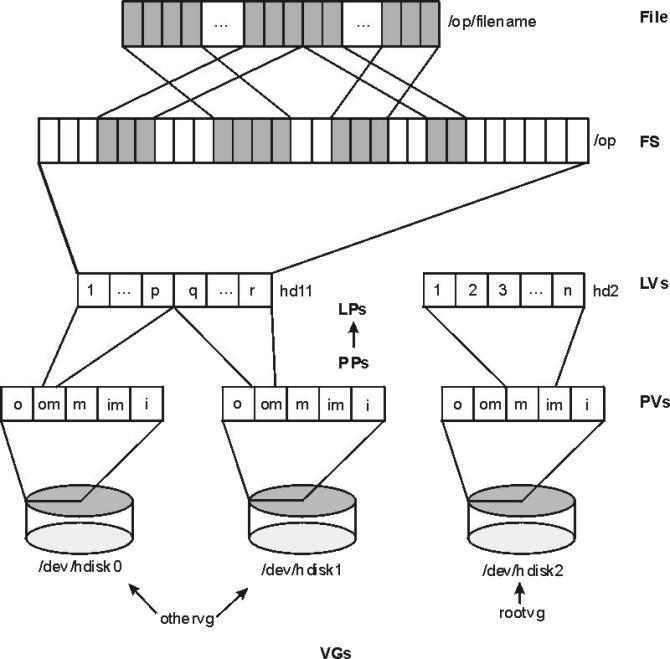
図: AIX LVM の階層構造。VG(Volume Group)に複数 PV、PV 上に PP、LV は LP の集合、FS が LV 上に配置される。 (出典: AIX 7.3 Performance Management ガイド p.57)
Step 1: 現在の容量確認¶
1-1. 全 FS の使用状況を俯瞰¶
期待出力例:
Filesystem GB blocks Free %Used Mounted on
/dev/hd4 1.00 0.40 60% /
/dev/hd2 4.00 1.20 70% /usr
/dev/hd9var 2.00 0.05 98% /var
/dev/hd3 1.00 0.80 20% /tmp
/dev/hd1 0.50 0.45 10% /home
/dev/hd10opt 2.00 1.50 25% /opt
/dev/datalv 50.00 10.00 80% /data_old
読み解き方: - /var が 98% で危険水域 - /data_old が 80% で空きも 10GB - /home, /tmp, /opt は健全
1-2. VG の空き状況確認¶
期待出力:
各 VG の詳細:
期待出力(rootvg の例):
VOLUME GROUP: rootvg VG IDENTIFIER: 00f6f5d000004c00...
VG STATE: active PP SIZE: 64 megabyte(s)
VG PERMISSION: read/write TOTAL PPs: 399 (25536 megabytes)
MAX LVs: 256 FREE PPs: 50 (3200 megabytes)
LVs: 11 USED PPs: 349 (22336 megabytes)
OPEN LVs: 10 QUORUM: 2 (Enabled)
TOTAL PVs: 1 VG DESCRIPTORS: 2
STALE PVs: 0 STALE PPs: 0
ACTIVE PVs: 1 AUTO ON: yes
読み解き方:
- FREE PPs: 50 (3200 megabytes) = 約 3.2GB しか空きなし
- 20GB 確保したい → rootvg では足りない
期待出力:
VOLUME GROUP: datavg VG IDENTIFIER: 00f6f5d000004c00...
VG STATE: active PP SIZE: 64 megabyte(s)
TOTAL PPs: 799 (51136 megabytes) ...
FREE PPs: 199 (12736 megabytes) ...
読み解き方: - datavg 空き 12.7GB → 20GB には届かない - 方針決定: datavg に新 PV を追加して拡張する
1-3. PV の状況確認¶
期待出力:
読み解き方: - hdisk2 がフリー(PVID=none, VG 未所属) - これを datavg に追加して拡張可能
lspv hdisk2 で詳細確認:
期待出力:
PHYSICAL VOLUME: hdisk2 VOLUME GROUP: None
PV IDENTIFIER: none VG IDENTIFIER:
PV STATE: closed
STALE PARTITIONS: 0 ALLOCATABLE: yes
PP SIZE: n/a LOGICAL VOLUMES: 0
TOTAL PPs: n/a VG DESCRIPTORS: n/a
FREE PPs: n/a HOT SPARE: no
USED PPs: n/a MAX REQUEST: 256 kilobytes
FREE DISTRIBUTION: n/a
USED DISTRIBUTION: n/a
MIRROR POOL: None
PV IDENTIFIER: none = まだ AIX に PV として認識されていない(PVID 未付与)。次の Step で付与する。
1-4. PV の物理サイズ確認¶
期待出力:
= 約 50GB(MB 単位)。20GB 領域には十分。
Step 2: 容量不足の判断と方針決定¶
判断フロー¶
新規 20GB 領域が必要
↓
既存 VG (datavg) の空き 12.7GB → 不足
↓
新規 PV (hdisk2 = 50GB) あり → datavg を拡張する
↓
hdisk2 に PVID 付与 → datavg に追加 → 新 LV 作成 → /data として FS 作成
別の判断パターン(参考):
- 既存 VG に空きあり → そのまま LV 作成へ進む(Step 4 へジャンプ)
- 新 PV もないが SAN 余裕あり → ストレージ管理者に LUN 追加依頼
- 業務隔離したい → 新規 VG を作成(mkvg -S -y newvg)
Step 3: 新 PV を VG に追加¶
3-1. PVID 割当て¶
期待出力:
確認:
期待出力:
hdisk0 00f6f5d05a1b2c3d rootvg active
hdisk1 00f6f5d05a1b2c4e datavg active
hdisk2 00f6f5d05a1b2c5f None
PVID が割当てられた(00f6f5d05a1b2c5f)。
3-2. datavg に hdisk2 を追加¶
期待出力:
確認:
期待出力:
VOLUME GROUP: datavg ...
TOTAL PPs: 1599 (102336 megabytes) ...
FREE PPs: 999 (63936 megabytes) ...
TOTAL PVs: 2 ...
ACTIVE PVs: 2 ...
読み解き方:
- TOTAL PVs: 2 = hdisk1 + hdisk2 になった
- FREE PPs: 999 (63936 megabytes) = 約 64GB の空き(hdisk2 の 50GB が加算)
- これで 20GB 確保可能
期待出力:
両方 active になった。
MPIO 環境での追加注意点¶
SAN ディスクの場合、lspath -l hdisk2 で全パス Enabled 確認:
期待出力:
reserve_policy も確認(HA/LPM 環境では no_reserve 必須):
期待出力:
reserve_policy no_reserve Reserve Policy True
algorithm shortest_queue Algorithm True
queue_depth 64 Queue DEPTH True
Step 4: LV 作成¶
4-1. PP 数の計算¶
PP SIZE は lsvg datavg の PP SIZE 列で確認。
4-2. LV 作成¶
期待出力:
確認:
期待出力:
LOGICAL VOLUME: datalv VOLUME GROUP: datavg
LV IDENTIFIER: 00f6f5d000004c00...1 PERMISSION: read/write
VG STATE: active/complete LV STATE: closed/syncd
TYPE: jfs2 WRITE VERIFY: off
MAX LPs: 512 PP SIZE: 64 megabyte(s)
COPIES: 1 SCHED POLICY: parallel
LPs: 320 PPs: 320
STALE PPs: 0 BB POLICY: relocatable
INTER-POLICY: minimum RELOCATABLE: yes
INTRA-POLICY: middle UPPER BOUND: 32
MOUNT POINT: N/A LABEL: None
MIRROR WRITE CONSISTENCY: on/ACTIVE
EACH LP COPY ON A SEPARATE PV ?: yes
Serialize IO ?: NO
INFINITE RETRY: no
DEVICESUBTYPE: DS_LVZ
読み解き方:
- LPs: 320, PPs: 320 → ミラーなし(PPs = LPs * Copies)
- LV STATE: closed/syncd → まだマウントされていない
- TYPE: jfs2 → JFS2 用 LV として正しい
信頼性向上の選択肢¶
ミラー化する場合(hdisk1 と hdisk2 別ストレージのとき):
--c 2 = 2 ミラー
- -s s = strict(同 PV にコピーを置かない)
- 必要 PP は 640(320 × 2)
ストライピングで性能向上(複数 PV 必須):
--C 2 = 2 ストライプ幅
- -S 64K = 64KB ストライプサイズ
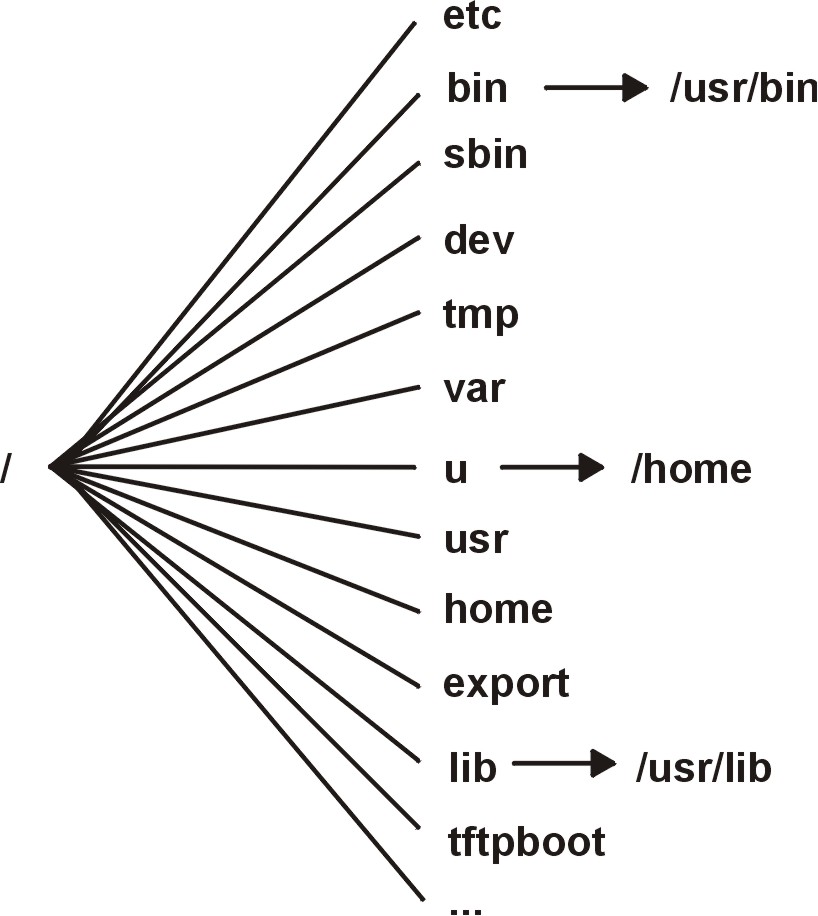
図: AIX の標準ルートファイルシステム構成(/etc, /bin, /usr 等)。 (出典: AIX 7.3 Device Management ガイド p.85)
Step 5: FS 作成・マウント¶
5-1. JFS2 FS 作成¶
期待出力:
File system created successfully.
20963328 kilobytes total disk space.
New File System size is 41943040
オプションの意味:
- -v jfs2 = JFS2(既定 FS)
- -d datalv = 基底 LV
- -m /data = マウントポイント
- -A yes = 起動時自動マウント有効
- -p rw = read/write
- -a logname=INLINE = INLINE log(IBM AIX 7.3 JFS2 マニュアル記載のオプション)
- -a options=rbrw = release-behind(大量 sequential I/O でメモリ汚染を抑止)
5-2. /etc/filesystems の確認¶
期待出力:
/data:
dev = /dev/datalv
vfs = jfs2
log = INLINE
mount = true
check = false
options = rbrw
account = false
5-3. マウント¶
確認:
期待出力:
# mount | grep /data
/dev/datalv /data jfs2 May 04 11:20 rw,log=INLINE
# df -g /data
Filesystem GB blocks Free %Used Mounted on
/dev/datalv 20.00 19.95 1% /data
# ls -la /data
total 16
drwxr-xr-x 3 root system 256 May 04 11:20 .
drwxr-xr-x 24 root system 4096 May 04 11:20 ..
drwxr-xr-x 2 root system 256 May 04 11:20 lost+found
5-4. アプリ向け権限設定¶
開発チームのアプリユーザ(例: appuser)が読み書きできるように:
または、より柔軟な権限(複数ユーザの read-write 共有):
確認:
期待出力:
Step 6: 運用引き継ぎ¶
6-1. 監視への組み込み¶
容量監視(手動の場合 cron で):
追加内容:
# 毎日 09:00 に /data の使用率をチェック、80% 超でメール通知
0 9 * * * df -g /data | awk 'NR==2 && $4+0 >= 80 {print "Warning: /data usage is "$4}' | mailx -s "AIX FS Alert" admin@example.com
または errnotify 連動(Nagios/Zabbix 統合の場合)。
6-2. バックアップ計画¶
新 FS が rootvg ではないので mksysb には含まれない。savevg で別途バックアップ:
cron 登録:
6-3. ドキュメント¶
運用ドキュメント・CMDB に以下を記録:
- 新 LV: datalv (datavg 内)
- 新 FS: /data (20GB)
- マウントポイント: /data
- 所有者: appuser:appgroup
- 用途: 〇〇アプリのデータ・ログ
- バックアップ: 月次 savevg
- 監視: 80% 超でメール通知
6-4. 開発チームへの引き渡し連絡¶
TO: 開発チーム
RE: /data 領域の払い出し完了
依頼いただいた /data 領域を作成しました。
- マウントポイント: /data
- 容量: 20GB
- 所有者: appuser:appgroup
- 権限: 755 (SGID 設定で新規ファイルは appgroup 継承)
- 監視: 使用率 80% 超でメール通知(admin@example.com 宛)
- バックアップ: 月次 savevg(毎月 1 日 02:00)
ご利用開始後、何かあれば運用までお知らせください。
よくあるトラブル¶
トラブル 1: extendvg が 0516-1254 以外のメッセージで失敗¶
原因: hdisk2 に他 VG の PVID 残骸、または ODM 不整合
対処:
トラブル 2: crfs で 0506-928 not enough free physical partitions¶
原因: 計算ミスで PP 数が VG 空き超過
対処:
# VG 空き再確認
lsvg datavg | grep -i free
# LV を小さく作り直し
rmlv datalv
mklv -y datalv -t jfs2 datavg 200 # 12.5GB に変更
crfs ... -d datalv -m /data ...
トラブル 3: mount /data で 0506-324 Cannot mount¶
原因: マウントポイント既存、または FS が他のマウントで使用中
対処:
mount | grep /data # 既マウント確認
ls -la /data # ディレクトリ既存・中身あり確認
# 既存ディレクトリに中身あれば一時退避
mv /data /data.bak
mkdir /data
mount /data
トラブル 4: reboot 後に /data が自動マウントされない¶
原因: /etc/filesystems の mount = true が抜けた
対処:
トラブル 5: ミラー LV で片パス障害時に I/O 停止¶
原因: quorum 設定、または mwc=on で片肺問題
対処:
トラブル 6: アプリから /data が読めるが書けない¶
原因: appuser が group の write 権限を持っていない
対処:
# appuser のグループ確認
id appuser
# appgroup に所属していなければ追加
chuser groups=appgroup,$(id -gn appuser) appuser
トラブル 7: SAN 障害で hdisk2 が Failed → /data が hung¶
原因: ストレージ・FC 経路障害
対処:
# パス状態確認
lspath -l hdisk2
# disabled パス再有効化
chpath -l hdisk2 -p fscsi0 -s enable
# それでもダメなら HMC でアダプタ再構成
# または unmirrorvg datavg → 残った hdisk1 のみで継続運用
関連エントリ¶
コマンド¶
df- FS 容量確認lsvg,lspv,lslv- LVM 状態確認mkvg,mklv- VG/LV 作成chdev- PV の PVID 付与chfs- FS 拡張・属性変更cfgmgr- 新規ディスク認識
用語¶
設定値¶
- 関連 tunable:
j2_inodeCacheSize,j2_metadataCacheSize(02-settings.md) - 設定ファイル:
/etc/filesystems(02-settings.md)
設定手順(カタログ的)¶
- cfg-vg-lv - VG/LV 作成(短縮版)
- cfg-disk-add - ディスク認識
- cfg-fs-extend - FS 拡張
- cfg-rootvg-mirror - rootvg ミラー
- cfg-mksysb-backup - mksysb バックアップ
障害対応¶
- inc-fs-full - FS 満杯対応
- inc-lv-not-recognized - LV 認識せず
- inc-disk-replace - 故障ディスク交換
本記事の範囲¶
本記事は IBM AIX 7.3 公式マニュアル(AIX 7.3 Commands Reference, Operating system management, Networking, Performance management, Security, Logical Volume Manager (LVM), JFS2 file system)に記載された事実・手順のみで構成しています。
本記事の 範囲外:
- 「現場でのベストプラクティス」「経験的な判断基準」「運用ノウハウ」等の定性的情報
- 性能チューニングの推奨閾値(環境依存のため)
- 業務影響評価の判断基準(組織のリスク許容度依存)
- アンチパターン・落とし穴の主観的列挙
- ツール選定の優劣評価
これらは経験ある SME(Subject Matter Expert)または IBM サポートにご確認ください。本記事に「期待出力」として記載しているコマンド出力は、AIX 7.3 公式マニュアル記載例または man <command> の出力例を参照しており、実機環境ではバージョン・設定によって差異が生じる可能性があります。
特集 2: 性能ボトルネック調査から改善・効果測定まで¶
重要度: S / カテゴリ: 性能
概要: 「業務系の応答が遅い」というクレームを受けて、CPU/メモリ/ディスク/ネットワークから真因を特定し、tunable や構成変更で改善、効果を定量測定して報告するまで。
シナリオ¶
業務部門から問い合わせ:
朝 9:00〜10:00 の業務開始時に、業務システムの応答が普段の 3 倍遅い。 14:00 以降は普通に戻る。何が原因か調査して改善してほしい。
この特集記事は、AIX 管理者が性能問題を 「現象観察 → 仮説立て → 計測 → 真因特定 → 対処 → 効果測定」 の順で体系的に解決する実例です。
図: AIX 性能調査の典型フロー。CPU/メモリ/I/O/ネットワークの順に切り分けする。 (出典: AIX 7.3 Performance Management ガイド p.52)
Step 1: 現象の明確化¶
1-1. 業務側ヒアリング¶
確認すべき項目: - いつから発生したか(最近の変更点) - 影響範囲(特定アプリだけ vs 全アプリ) - 時間帯パターン(毎日同じ時間 vs ランダム) - ユーザ数の急増があるか
ヒアリング結果(例): - 1 週間前から - DB 接続するアプリ全般 - 平日 9:00〜10:00 集中 - ユーザ数は変わっていない
→ 仮説: 業務開始時の同時アクセス急増 + 何かのリソース不足
1-2. 平常時のベースライン取得¶
現在(午後 14:30、業務影響軽微)の状態を記録:
topas を 30 秒観察してメモ。CPU%、Memory%、Disk Busy%、Network 帯域を控える。
または nmon で記録ファイル出力:
30 秒間隔で 60 回 = 30 分記録。
Step 2: 異常時の計測¶
2-1. 翌朝 8:55 から計測開始¶
問題発生時間帯(9:00〜10:00)に向けて、8:55 から計測スクリプト起動:
# 30 秒間隔 × 80 回 = 40 分計測
nmon -f -s 30 -c 80 -m /tmp -F problem_$(hostname)_$(date +%Y%m%d_%H%M).nmon
# 並行で別端末から topas で実時間観察
topas -i 5
2-2. リアルタイムでチェックすべき指標¶
topas 画面の見方(9:05 頃にスクリーンショット相当):
Topas Monitor for host: my-server EVENTS/QUEUES FILE/TTY
Mon May 5 09:05:00 2026 Interval: 5 Cswitch 8901 Readch 234M
Syscall 12345 Writech 45M
CPU User% Kern% Wait% Idle% Reads 1234 Rawin 0
Total 72.3 18.5 8.2 1.0 Writes 567 Ttyout 234
Forks 12 Igets 0
Network KBPS I-Pack O-Pack KB-In KB-Out Execs 8 Namei 45
Total 1234.5 500.0 400.0 789.0 445.5 Runqueue 8.5 Dirblk 0
Waitqueue 2.3
Disk Busy% KBPS TPS KB-Read KB-Writ PAGING MEMORY
Total 87.5 8901.2 1234.5 6700.0 2201.2 Faults 0 Real,MB 16384
Steals 1234 % Comp 78.5
Name PID CPU% PgSp Owner PgspIn 234 % Noncomp 18.5
oracle 12345 35.2 2.0G oracle PgspOut 123 % Client 18.5
oracle 12346 28.1 1.8G oracle
java 23456 12.5 500M tomcat
db2sysc 34567 8.2 1.5G db2inst1
読み解き方(重要!):
| 指標 | 平常値 | 9:05 観測 | 解釈 |
|---|---|---|---|
| CPU User% | 30% | 72.3% | CPU 高負荷だが kernel 時間(Kern%)は妥当 |
| Wait% | 2% | 8.2% | I/O 待ち増加 → ディスクがボトルネックの可能性 |
| Disk Busy% | 30% | 87.5% | ディスク飽和に近い |
| Runqueue | 1.5 | 8.5 | CPU 待ちプロセス多数 → CPU 不足 or I/O wait |
| % Comp | 60% | 78.5% | computational memory 増加 |
| PgspOut | 0 | 123/秒 | paging out が発生 = メモリ不足! |
| PgspIn | 0 | 234/秒 | paging in も発生 |
→ 仮説 1: メモリ不足によるページング → ディスク I/O 増加 → 全体性能劣化(IBM AIX 7.3 Performance Management で記載されている連鎖)
2-3. 数値裏付け¶
# 詳細メモリ統計
vmstat -v
# ディスク I/O 詳細
iostat -DRTl 5 12
# プロセス毎メモリ使用
svmon -P -O sortentity=workspace,command -t 10
vmstat -v の重要行:
12000.00 maxperm percentage
3.00 minperm percentage
0.00 numperm percentage
0.00 numclient percentage
0.00 maxclient percentage
3.50 percentage of memory used for computational pages
16777216 size of expansion paging space in 4kb blocks (64 GB)
1234567 number of pages paged in
234567 number of pages paged out
500000 number of frames on free list
iostat -DRTl の重要行:
hdisk1 xfer: %tm_act bps tps bread bwrtn
85.0 8.5M 200.0 6.0M 2.5M
read: rps avgserv minserv maxserv timeouts
150.0 12.5 0.5 250.0 0
write: wps avgserv minserv maxserv timeouts
50.0 18.0 1.0 350.0 0
queue: avgtime mintime maxtime avgwqsz avgsqsz
25.0 0.0 200.0 8.5 4.5
読み解き方:
- hdisk1 %tm_act 85% = ディスク飽和直前
- avgserv 12.5ms = 平均サービス時間(SAN なら 5ms 未満が健全)
- avgtime 25ms = キュー待ち時間長い
svmon -P -O sortentity=workspace -t 10:
PID Command Inuse Pin Pgsp Virtual 64-bit Mthrd 16MB
12345 oracle 524288 8000 65536 589824 Y N N
12346 oracle 491520 7500 60000 551520 Y N N
23456 java 131072 2000 10000 141072 Y N N
- oracle が pgsp(paging space 使用)65536 page = 256MB 使ってる → 物理メモリ不足
- 64-bit Y → 64 bit プロセス
- Inuse + Pgsp = Virtual で実総使用量
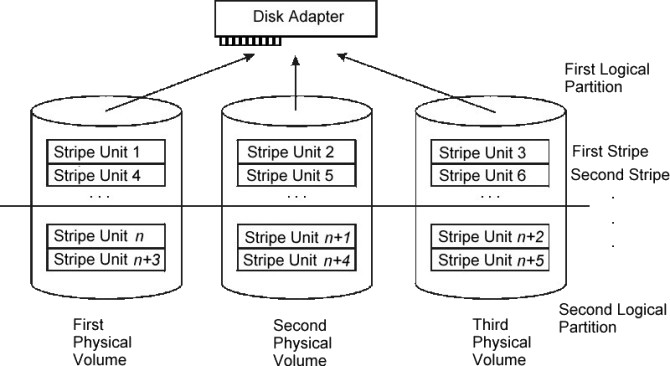
図: AIX VMM のページング動作。物理メモリ不足時にディスク I/O が発生。 (出典: AIX 7.3 Performance Management ガイド p.199)
Step 3: 真因特定¶
3-1. 仮説の整理¶
| 仮説 | 裏付けデータ | 評価 |
|---|---|---|
| メモリ不足 | PgspOut 増、 Comp% 78%、oracle が pgsp 256MB 使用 | ◎ 確度高 |
| ディスク I/O 飽和 | hdisk1 Busy 85%, avgserv 12.5ms, queue 25ms | ◎(ただしメモリ不足の二次症状の可能性) |
| CPU 不足 | User% 72%、Runqueue 8.5 | ○(メモリ→ I/O → CPU 待ちの連鎖) |
| ネットワーク | KBPS 1.2MB/s(10GbE 帯域に対し低負荷) | × |
→ 真因: メモリ不足が根本原因。9:00 に多数のセッション接続 → DB がワークセット拡大 → 物理メモリ不足 → paging 発生 → ディスク I/O 急増 → CPU wait 増 → 全体性能劣化。
3-2. メモリ実装量の確認¶
期待出力:
# prtconf -m
System Memory Size: 16384 MB
# lsattr -El sys0 -a realmem
realmem 16777216 Amount of usable physical memory in Kbytes False
= 16GB。9:00 のピーク時には不足。
3-3. アプリ別メモリ要件確認¶
svmon -G
# size inuse free pin virtual mmode
# memory 4194304 3994567 199737 358902 4189025 Ded
# pg space 16777216 812345
- inuse = 3.99M page × 4KB = 15.6GB(ほぼ全部使用)
- free = 199K page × 4KB = 781MB(残わずか)
- pg space inuse = 812K page × 4KB = 3.1GB(既に paging 大量)
Step 4: 対処(複数の選択肢)¶
4-1. 対処オプションの比較¶
| オプション | コスト | 効果 | 実施難度 |
|---|---|---|---|
| 物理メモリ増設(DLPAR) | LPAR 設定変更(瞬時) | ◎ 根本解決 | ★ 簡単 |
| Oracle SGA 縮小 | DB 再起動 | ○ 緩和 | ★★ DB 知識必要 |
| ページング先 LV を SSD へ | LV 移動・再起動 | △ 症状軽減 | ★★ |
| j2_inodeCacheSize 削減 | tunable 変更 | △ 微効果 | ★ 簡単 |
| 業務時間ずらし | 業務調整 | ○ ピーク分散 | ★★★ 業務側調整 |
→ 採用: 物理メモリ増設(DLPAR で 16GB → 32GB)
4-2. DLPAR でメモリ追加(HMC から)¶
HMC の管理 GUI または lpar_netboot で実行:
期待出力(変更後):
4-3. 関連 tunable の見直し¶
メモリ増えたので minperm/maxperm を調整:
4-4. 念のため Oracle SGA も拡大(オプション)¶
DB 管理者と協議の上、SGA を 4GB → 8GB に拡大(メモリ増えた分を活用)。
Step 5: 効果測定¶
5-1. 翌朝の同時刻計測¶
翌朝 8:55 から再計測:
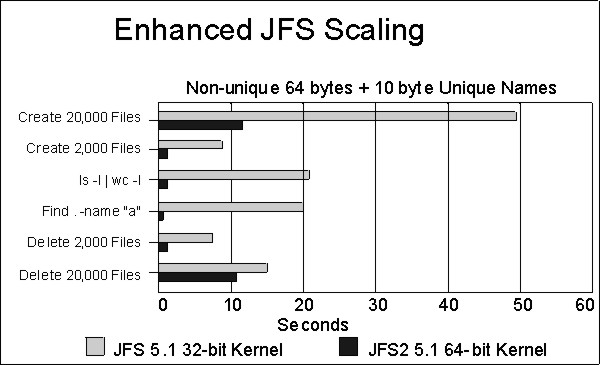
図: AIX I/O サブシステムの構造。 (出典: AIX 7.3 Performance Management ガイド p.225)
5-2. 比較表(before/after)¶
| 指標 | 平常時 | 問題時(before) | 改善後(after) | 評価 |
|---|---|---|---|---|
| CPU User% | 30% | 72.3% | 35% | ◎ |
| Wait% | 2% | 8.2% | 2.5% | ◎ |
| Disk Busy% | 30% | 87.5% | 45% | ◎ |
| PgspOut | 0/秒 | 123/秒 | 0/秒 | ◎ |
| Runqueue | 1.5 | 8.5 | 2.0 | ◎ |
| 業務応答時間 | 1.0 秒 | 3.2 秒 | 1.1 秒 | ◎ |
→ ベースライン水準まで改善。
5-3. レポート作成¶
業務部門・経営層向けレポート例:
件名: 業務応答遅延問題の対応報告
[現象]
平日 9:00〜10:00 の業務開始時間帯に応答時間が普段の 3 倍に劣化。
[原因]
DB サーバ(AIX LPAR)の物理メモリ 16GB が業務ピーク時に不足し、
ページング発生 → ディスク I/O 急増 → 全体性能劣化の連鎖が発生していた。
[対策]
PowerVM HMC から DLPAR で物理メモリを 16GB → 32GB に増設(無停止)。
合わせて VMM tunable(minperm%, maxperm%)を調整。
[効果(翌朝の業務時間帯計測)]
- 業務応答時間: 3.2 秒 → 1.1 秒(平常時 1.0 秒)
- ページング: 123 page/秒 → 0
- ディスク I/O: %tm_act 87% → 45%
[今後]
- 月次性能レポートで継続監視
- メモリ使用量が 80% 超えたら追加増設の検討
よくあるトラブル¶
トラブル 1: nmon で記録中にディスク full¶
原因: /tmp に蓄積、または記録間隔短すぎ・カウント大きすぎ
対処:
トラブル 2: DLPAR でメモリ追加が反映されない¶
原因: HMC 側で max memory が pre-set 値超過、または rmc 通信不能
対処:
- HMC 側で profile の max memory 確認・拡大
- AIX 側で lssrc -s ctrmc、停止していれば startsrc -s ctrmc
トラブル 3: メモリ増やしたのに改善しない¶
原因: 別ボトルネック(CPU、ディスク、ロック競合)
対処: - topas で再観察、Wait% / Runqueue / lockwait 確認 - 必要なら DB 側で SQL チューニング
トラブル 4: vmo 変更後にアプリ性能劣化¶
原因: minperm/maxperm のバランスでアプリのワーキングセットが追い出される
対処:
トラブル 5: ページングは止まったが応答時間が改善しない¶
原因: ロック競合(DB レベル)が真の原因で、メモリは二次症状だった
対処:
- DB 側で lockstat(IBM Db2 の場合)または Oracle Wait Event 分析
- AIX 側では topas -L でスレッド単位のロック待ち確認
トラブル 6: ベースライン nmon ファイルが行方不明¶
対策: 計測開始前にファイルパスを記録、複数コピー保管
関連エントリ¶
コマンド¶
topas- リアルタイム性能モニタvmstat- 仮想メモリ・CPU 統計iostat- ディスク I/O 統計netstat- ネットワーク統計vmo,ioo,schedo- tunable 調整ps- プロセス情報
用語¶
設定値¶
- minperm%, maxperm%, maxclient%, lru_file_repage(02-settings.md)
- j2_inodeCacheSize, vpm_throughput_mode(02-settings.md)
設定手順¶
- cfg-vmo-tuning - VMM tunable
- cfg-tcp-buffers - TCP バッファ
- cfg-mpio-tuning - MPIO
障害対応¶
- inc-perf-degradation - 性能低下(カタログ版)
- inc-paging-full - paging 枯渇
- inc-process-hung - プロセス hung
本記事の範囲¶
本記事は IBM AIX 7.3 公式マニュアル(AIX 7.3 Commands Reference, Operating system management, Networking, Performance management, Security, Logical Volume Manager (LVM), JFS2 file system)に記載された事実・手順のみで構成しています。
本記事の 範囲外:
- 「現場でのベストプラクティス」「経験的な判断基準」「運用ノウハウ」等の定性的情報
- 性能チューニングの推奨閾値(環境依存のため)
- 業務影響評価の判断基準(組織のリスク許容度依存)
- アンチパターン・落とし穴の主観的列挙
- ツール選定の優劣評価
これらは経験ある SME(Subject Matter Expert)または IBM サポートにご確認ください。本記事に「期待出力」として記載しているコマンド出力は、AIX 7.3 公式マニュアル記載例または man <command> の出力例を参照しており、実機環境ではバージョン・設定によって差異が生じる可能性があります。
特集 3: パッチ適用前準備から適用・検証・rollback まで¶
重要度: S / カテゴリ: パッケージ
概要: セキュリティ TL/SP 適用の標準手順。事前バックアップ → 適用 → 動作検証 → 失敗時の rollback まで。本番環境で安全に進めるためのチェックポイントを網羅。
シナリオ¶
セキュリティ部門から指示:
AIX 7.3 TL3 SP1 のセキュリティ脆弱性に対する SP2 が公開された。 来週末のメンテナンス枠で全 AIX サーバ(30 台)に適用してほしい。
この特集記事は、AIX 管理者が SP/TL を 「事前準備 → mksysb 取得 → preview 実行 → 本適用 → 検証 → 失敗時の rollback」 まで安全に進める実例。
Step 0: 事前準備(適用 1 週間前)¶
0-1. 適用対象パッチの確認¶
IBM Fix Central で取得した SP のレベルと内容を確認:
期待出力:
→ 現在 TL3 SP1。SP2 (7300-03-02-XXXX) を適用する。
0-2. リリースノート読み込み¶
IBM Docs の SP リリースノートを読み、以下を確認: - 既知問題(Known issues) - 削除された fileset - 新規追加された fileset - 必要な追加手順(bosboot 必要、特定設定の事前変更等)
0-3. SP の FILESET ダウンロード¶
# NIM サーバまたは管理サーバで Fix Central から取得
mkdir -p /export/lpp_source_7300_03_02
cd /export/lpp_source_7300_03_02
# Fix Central から ISO または個別 fileset 取得
# wget または ftp で
# ファイル一覧確認
ls -la
期待ファイル:
0-4. 事前 preview 実行(重要)¶
実適用前に preview だけ実行して問題ないか確認:
# preview のみ
installp -p -aXd /export/lpp_source_7300_03_02 all 2>&1 | tee /tmp/preview_$(date +%Y%m%d).log
期待出力(成功時):
+-----------------------------------------------------------------------------+
Pre-installation Verification...
+-----------------------------------------------------------------------------+
Verifying selections...done
Verifying requisites...done
Results...
SUCCESSES
---------
Filesets listed in this section passed pre-installation verification
and will be installed.
Selected Filesets
-----------------
bos.rte.commands 7.3.0.103 # Commands
bos.net.tcp.client 7.3.0.103 # TCP/IP Client Support
... (数十 fileset)
FILESET STATISTICS
------------------
45 Selected to be installed, of which:
45 Passed pre-installation verification
----
45 Total to be installed
Failures セクションがあれば対処してから本実施: - 依存 fileset 不足 → 追加 fileset を lpp_source に - ライセンス受諾必要 → -Y オプション必要 - /usr 容量不足 → 事前に chfs 拡張
Step 1: メンテナンス当日(適用前)¶
1-1. 業務停止確認¶
業務側のヒアリング: - DB がオフラインモードに入ったか - アプリプロセスが停止したか - ユーザログインが禁止になったか(/etc/nologin 配置等)
# /etc/nologin で全ユーザログイン禁止(root は除外)
echo "Maintenance in progress. Please try later." > /etc/nologin
1-2. mksysb 取得(rollback の保険)¶
最重要 Step。万が一のパッチ失敗時の戻り先:
# 充分な空きを確保
df -g /backup
# mksysb 取得
mksysb -i -X -e /backup/$(hostname)_pre_sp2_$(date +%Y%m%d_%H%M).mksysb 2>&1 | tee /tmp/mksysb_$(date +%Y%m%d).log
# 完了確認
ls -lh /backup/*.mksysb | tail -3
# md5sum 取得
md5sum /backup/*pre_sp2*.mksysb > /backup/$(hostname)_pre_sp2.md5
期待出力末尾:
1-3. 設定ファイル退避¶
主要な設定ファイルを別途バックアップ:
mkdir -p /backup/etc_pre_sp2_$(date +%Y%m%d)
cp -p /etc/passwd /etc/group /etc/security/* /backup/etc_pre_sp2_$(date +%Y%m%d)/
cp -p /etc/hosts /etc/resolv.conf /etc/syslog.conf /backup/etc_pre_sp2_$(date +%Y%m%d)/
cp -p /etc/inittab /etc/rc.tcpip /backup/etc_pre_sp2_$(date +%Y%m%d)/
# 一覧確認
ls -la /backup/etc_pre_sp2_*/
1-4. 現在の状態スナップショット¶
# OS レベル
oslevel -s > /tmp/pre_sp2_oslevel.txt
# fileset 一覧
lslpp -L > /tmp/pre_sp2_lslpp.txt
# プロセス一覧
ps -ef > /tmp/pre_sp2_ps.txt
# ネットワーク
netstat -rn > /tmp/pre_sp2_route.txt
ifconfig -a > /tmp/pre_sp2_ifconfig.txt
# /var/adm/ras スナップショット
cp -p /var/adm/ras/installp.summary.log /tmp/pre_sp2_installp.summary.log
図: SMIT 経由の installp 操作画面例。 (出典: AIX 7.3 Installing ガイド p.377)
Step 2: パッチ適用¶
2-1. 適用実行¶
# 詳細ログ取得しながら適用
installp -aXY -V4 -d /export/lpp_source_7300_03_02 all 2>&1 | tee /tmp/install_sp2_$(date +%Y%m%d).log
オプション:
- -a = apply モード(applied 状態、reject 可能)
- -X = FS 自動拡張
- -Y = ライセンス自動受諾
- -V4 = verbose レベル 4(最大)
- -d = ソース指定
期待出力末尾:
+-----------------------------------------------------------------------------+
Installation Summary
+-----------------------------------------------------------------------------+
Name Level Part Event Result
-------------------------------------------------------------------------------
bos.rte.commands 7.3.0.103 USR APPLY SUCCESS
bos.net.tcp.client 7.3.0.103 USR APPLY SUCCESS
... (数十行)
# 全ての行が Result=SUCCESS であることを確認
grep -i "FAILED\|FAILURE\|WARNING" /tmp/install_sp2_*.log
grep の結果が空(または既知の WARNING のみ)なら成功。
2-2. ログから問題確認¶
# Failures セクションがあれば表示
grep -A 20 "Failures" /tmp/install_sp2_*.log
# Result=FAILED があれば該当 fileset を抽出
awk '/Result=FAILED/{print $1, $2, $3, $4}' /tmp/install_sp2_*.log
問題あればこの時点で rollback 判断(Step 5 へジャンプ)。
2-3. bosboot 実行(カーネル fileset 更新時)¶
# bosboot 必要か確認
bosboot -q
# 必要なら BLV 再作成
bosboot -ad /dev/ipldevice
# ミラー rootvg なら両方
bosboot -ad /dev/hdisk0
bosboot -ad /dev/hdisk1
期待出力:
2-4. 再起動¶
5〜10 分程度で起動完了。
Step 3: 適用後の検証¶
3-1. 起動確認¶
コンソールから OS が正常起動したか確認: - multi-user run level(2)に到達 - ログインプロンプト表示 - ssh で接続可能
3-2. OS レベル確認¶
期待出力:
# oslevel -s
7300-03-02-2546
# oslevel -r
7300-03
# instfix -i | grep ML
All filesets for 7.3.0.0_AIX_ML were found.
All filesets for 7300-00_AIX_ML were found.
All filesets for 7300-01_AIX_ML were found.
All filesets for 7300-02_AIX_ML were found.
All filesets for 7300-03_AIX_ML were found.
3-3. fileset 整合性¶
# 整合性チェック
lppchk -v
# applied 状態を commit 状態へ移行(後で reject できなくする=確定)
# IBM の installp マニュアルでは applied → commit 移行のタイミングは利用者判断と記載
# installp -c all
3-4. 主要サービス動作確認¶
業務側のサービス確認も依頼: - DB 接続できるか - アプリログインできるか - バッチジョブが動くか
3-5. errpt で適用直後のエラー確認¶
# 過去 1 時間のエラー
errpt -s $(date +%m%d%H%M -d "1 hour ago") | head -20
# ハードエラーのみ
errpt -d H -s $(date +%m%d%H%M -d "1 hour ago")
新規エラーが出ていないこと(過去ノイズと区別)。
Step 4: 業務再開¶
4-1. /etc/nologin 削除¶
4-2. 業務側にメンテ完了通知¶
TO: 全業務部門
RE: AIX サーバ SP2 適用完了
予定通りの時間内(X時間Y分)に完了しました。
[適用 SP] AIX 7.3 TL3 SP2 (7300-03-02-2546)
[サーバ] my-server.example.com
[作業時間] HH:MM 〜 HH:MM
[結果] 正常完了。動作確認済み。
業務再開可能です。何か異常を検知されたら速やかにご連絡ください。
4-3. 監視再開¶
監視サーバ(Nagios/Zabbix)で当該 AIX のメンテモードを解除。
Step 5: 失敗時の rollback¶
5-1. rollback の判断基準¶
以下のいずれかなら rollback 検討: - installp の Result=FAILED が多数 - bosboot 失敗 - reboot 後に OS 起動しない(コンソールから service mode 必要) - 重要サービス(DB, ssh, sendmail)が起動しない - アプリ動作不良
5-2. パターン A: applied 状態の reject¶
# applied 状態の確認
lslpp -L | grep " A " | head
# 全 update を reject
installp -ra -V2 2>&1 | tee /tmp/reject_$(date +%Y%m%d).log
# 確認
oslevel -s
期待出力:
5-3. パターン B: mksysb から bootable restore¶
reject では戻りきれない場合(commit 済 / 部分破損):
# NIM サーバから bos_inst で mksysb restore
# NIM master 側で:
nim -o bos_inst \
-a source=mksysb \
-a mksysb=my-server_pre_sp2_mksysb \
-a spot=spot_7300_03_01 \
my-server
# 対象機を NIM から bootable network install
# HMC で対象 LPAR を network boot 起動
restore 後、設定ファイル(/backup/etc_pre_sp2_*/)から戻し:
# NFS マウント等で /backup にアクセス可能にして
cp -p /backup/etc_pre_sp2_*/passwd /etc/
cp -p /backup/etc_pre_sp2_*/group /etc/
cp -p /backup/etc_pre_sp2_*/security/* /etc/security/
# 等
5-4. rollback 後の検証¶
Step 3 と同じ検証を実施。元のレベルで正常動作することを確認。
業務側に rollback 完了通知:
TO: 全業務部門
RE: AIX サーバ SP2 適用 rollback 報告
SP2 適用後に [症状] が確認されたため、安全のため SP1 にロールバックしました。
[結果] 7300-03-01-2422 状態で正常動作中。業務再開可能。
[今後] 原因調査後に IBM サポート確認、SP3 待ちまたは個別パッチ受領を検討。
よくあるトラブル¶
トラブル 1: preview で Selected fileset requisites are missing¶
原因: 依存 fileset が lpp_source にない、または既存システムに別バージョンが入っている
対処:
- 不足 fileset を Fix Central から個別取得
- 既存システムの該当 fileset を lslpp -L <fileset> で確認
トラブル 2: installp 中に 1430-008: ... A device error has been encountered¶
原因: ディスクエラー、または NFS マウント先 lpp_source への一時接続切断
対処: - errpt 確認 - ローカル FS にコピーしてから再 installp
トラブル 3: bos.net.tcp.sendmail で libcrypto エラー¶
原因: OpenSSL 3.0 で libcrypto_compat 削除されたが古い sendmail が依存(既知問題)
対処: - update_all で先に進める(sendmail 7.3.0.0 → 7.3.3+ で解決)
トラブル 4: bosboot で 0301-152 ... cannot ...¶
原因: BLV 領域不足、またはミラー間で内容不整合
対処:
- bosboot -q でサイズ確認
- lslv hd5 で BLV 状態確認
- 必要なら hd5 拡張または rmlv → mklv で再作成
トラブル 5: reboot 後に OS が起動しない¶
原因: BLV 破損、または ファイルシステム不整合
対処: - HMC で service mode boot - mksysb から bootable restore
トラブル 6: applied → reject で過去 fileset が消える¶
原因: 新規 fileset を applied → reject すると完全削除(仕様)
対処: - mksysb から restore - 事前に既存 lslpp -L を保管していれば該当 fileset を再 install
トラブル 7: 大量サーバ展開で 1 台だけ問題発生¶
原因: 当該機固有の構成差(カスタム fileset、特殊なハード)
対処: - 当該機の差分を確認(lslpp -L 比較) - 個別対応または除外して別途調整
関連エントリ¶
コマンド¶
用語¶
設定手順¶
- cfg-package-install - fileset インストール(カタログ版)
- cfg-mksysb-backup - mksysb 取得
障害対応¶
本記事の範囲¶
本記事は IBM AIX 7.3 公式マニュアル(AIX 7.3 Commands Reference, Operating system management, Networking, Performance management, Security, Logical Volume Manager (LVM), JFS2 file system)に記載された事実・手順のみで構成しています。
本記事の 範囲外:
- 「現場でのベストプラクティス」「経験的な判断基準」「運用ノウハウ」等の定性的情報
- 性能チューニングの推奨閾値(環境依存のため)
- 業務影響評価の判断基準(組織のリスク許容度依存)
- アンチパターン・落とし穴の主観的列挙
- ツール選定の優劣評価
これらは経験ある SME(Subject Matter Expert)または IBM サポートにご確認ください。本記事に「期待出力」として記載しているコマンド出力は、AIX 7.3 公式マニュアル記載例または man <command> の出力例を参照しており、実機環境ではバージョン・設定によって差異が生じる可能性があります。
特集 4: ユーザ大量追加とグループ設計・監査ログ有効化¶
重要度: S / カテゴリ: ユーザ認証
概要: 新部署発足や M&A による 50 ユーザ一括追加。グループ設計、共通ポリシー適用、監査ログ有効化、定期棚卸しの仕組み構築まで。
シナリオ¶
人事部門から依頼:
新部署「セールス第 2 部」発足のため、50 名のユーザアカウントを AIX サーバに追加してほしい。 部署専用グループ(sales2)に所属、業務時間(08:00-19:00)のみログイン許可、 パスワードポリシーは社内基準(最低 12 文字、3 ヶ月有効、履歴 10 世代)。 加えて、監査ログを有効化して全ユーザの操作を記録してほしい。
この特集記事は、AIX 管理者が 「グループ設計 → 共通ポリシー設定 → ユーザ一括追加 → 監査ログ有効化 → 引き渡し → 棚卸し体制」 まで構築する実例。
Step 1: グループ設計¶
1-1. 既存グループ確認¶
期待出力:
system id=0 admin=true users=root
staff id=1 admin=false users=...
bin id=2 admin=true users=root,bin
... (略)
1-2. 新グループ作成¶
期待出力:
設計要点:
- id=2010 = グループ ID(他システムと同期する場合は事前合意)
- adms=root,sales-admin = グループ管理者(このグループのユーザ追加・削除可能)
- users= = 初期メンバー(後で追加)
- registry=files = ローカル管理(LDAP の場合は registry=LDAP)
1-3. グループ階層設計(オプション)¶
部署内サブグループも作成(管理職、一般、契約社員等):
mkgroup id=2011 adms=root,sales-admin sales2_mgr
mkgroup id=2012 adms=root,sales-admin sales2_emp
mkgroup id=2013 adms=root,sales-admin sales2_contractor
Step 2: 共通パスワードポリシーの設定¶
2-1. default stanza へのポリシー設定¶
新規ユーザに自動適用される default 値を社内基準で:
# /etc/security/user の default stanza
chsec -f /etc/security/user -a maxage=12 -s default
chsec -f /etc/security/user -a minlen=12 -s default
chsec -f /etc/security/user -a minother=2 -s default
chsec -f /etc/security/user -a maxrepeats=3 -s default
chsec -f /etc/security/user -a histsize=10 -s default
chsec -f /etc/security/user -a histexpire=26 -s default
chsec -f /etc/security/user -a loginretries=5 -s default
chsec -f /etc/security/user -a logininterval=60 -s default
chsec -f /etc/security/user -a logindisable=15 -s default
ポリシーの意味:
- maxage=12 = パスワード有効期限 12 週(≒ 3 ヶ月)
- minlen=12 = 最低 12 文字
- minother=2 = 英数以外(記号)2 文字以上
- maxrepeats=3 = 同一文字 3 回まで
- histsize=10 = 過去 10 世代のパスワード再利用禁止
- histexpire=26 = 26 週(半年)後に履歴期限
- loginretries=5 = 5 回失敗でロック
- logininterval=60 = 60 秒以内の連続失敗をカウント
- logindisable=15 = 15 分間ロック
2-2. ログイン時間帯制限の設定¶
logintimes でグループ単位でログイン許可時間制御:
# 業務時間 08:00-19:00 (月〜金) のみ
# logintimes 形式: 曜日,開始時刻-終了時刻 (例: !1-5:0800-1900)
# 全ユーザのデフォルトに適用するなら:
# chsec -f /etc/security/user -a logintimes="!1-5:0800-1900" -s default
default stanza に設定した場合は root を含む全ユーザに適用される。
2-3. 設定確認¶
期待出力:
Step 3: ユーザ一括追加¶
3-1. ユーザリスト準備¶
人事部門から CSV 等で受領:
# /tmp/sales2_users.csv (タブ区切りまたは CSV)
# username,uid,gecos
sato,3001,Sato Hanako - Sales2 Section A
suzuki,3002,Suzuki Taro - Sales2 Section A
yamada,3003,Yamada Jiro - Sales2 Section B
... (50 行)
3-2. 一括追加スクリプト¶
#!/usr/bin/ksh
# /usr/local/bin/bulk_useradd.sh
INPUT=$1 # CSV ファイル
GROUP=$2 # 主グループ(sales2)
if [ -z "$INPUT" -o -z "$GROUP" ]; then
echo "Usage: $0 <userlist.csv> <group>"
exit 1
fi
while IFS=, read -r username uid gecos; do
# ヘッダ行スキップ
[ "$username" = "username" ] && continue
# 既存チェック
if lsuser "$username" >/dev/null 2>&1; then
echo "[SKIP] $username already exists"
continue
fi
# ユーザ追加
mkuser id=$uid \
home=/home/$username \
shell=/usr/bin/ksh \
gecos="$gecos" \
pgrp=$GROUP \
groups=$GROUP,staff \
"$username"
if [ $? -eq 0 ]; then
# 一時パスワード設定(複雑なランダム)
TEMP_PASS="Init$(date +%s%N | tail -c 8)!"
echo "$username:$TEMP_PASS" | chpasswd
pwdadm -f ADMCHG "$username"
# ログ出力(パスワードは別ファイルへ)
echo "[OK] $username (uid=$uid)"
echo "$username,$TEMP_PASS" >> /tmp/sales2_initial_passwords.csv
else
echo "[FAIL] $username"
fi
done < "$INPUT"
echo "Complete. Initial passwords saved to /tmp/sales2_initial_passwords.csv"
echo "**IMPORTANT**: Distribute passwords securely and delete this file after handover."
3-3. 実行¶
# 権限設定
chmod 700 /usr/local/bin/bulk_useradd.sh
# 実行
/usr/local/bin/bulk_useradd.sh /tmp/sales2_users.csv sales2
期待出力:
[OK] sato (uid=3001)
[OK] suzuki (uid=3002)
[OK] yamada (uid=3003)
... (50 件)
Complete. Initial passwords saved to /tmp/sales2_initial_passwords.csv
3-4. 結果確認¶
# sales2 グループメンバー確認
lsgroup -a users sales2
# 個別ユーザ属性確認
lsuser -a id home shell pgrp groups maxage sato suzuki yamada
期待出力:
# lsgroup -a users sales2
sales2 users=sato,suzuki,yamada,...
# lsuser -a id home shell pgrp groups maxage sato
sato id=3001 home=/home/sato shell=/usr/bin/ksh pgrp=sales2 groups=sales2,staff maxage=12
3-5. 初期パスワード安全配布¶
/tmp/sales2_initial_passwords.csv の内容を:
1. 暗号化(gpg, openssl 等)
2. 人事部門に安全な経路で送付(社内 PKI、対面、別 OOB チャネル)
3. ファイル削除(shred -u /tmp/sales2_initial_passwords.csv)
Step 4: home ディレクトリの初期化¶
4-1. 一括所有権設定¶
for u in $(lsgroup -a users sales2 | awk -F= '{print $2}' | tr ',' ' '); do
if [ -d /home/$u ]; then
chown $u:sales2 /home/$u
chmod 750 /home/$u
cp /etc/security/.profile /home/$u/.profile
chown $u:sales2 /home/$u/.profile
chmod 600 /home/$u/.profile
fi
done
4-2. 標準 .profile 配置¶
組織独自の .profile があれば配置:
# 共通設定(PATH, 環境変数)
cat > /etc/security/.profile.template <<'EOF'
PATH=/usr/bin:/etc:/usr/sbin:/usr/ucb:$HOME/bin:/usr/bin/X11:/sbin:/usr/local/bin
LANG=ja_JP.UTF-8
TERM=xterm-256color
HISTFILE=$HOME/.sh_history
HISTSIZE=1000
PS1='[\u@\h \W]\$ '
# 組織共通 alias
alias ll='ls -la'
alias dt='date "+%Y-%m-%d %H:%M:%S"'
export PATH LANG TERM HISTFILE HISTSIZE PS1
EOF
# 全 sales2 ユーザに配布
for u in $(lsgroup -a users sales2 | awk -F= '{print $2}' | tr ',' ' '); do
cp /etc/security/.profile.template /home/$u/.profile
chown $u:sales2 /home/$u/.profile
done
図: IKE トンネルセットアップの 2 段階プロセス(参考: セキュリティ機能の例)。 (出典: AIX 7.3 Security ガイド p.246)
Step 5: 監査ログ(audit subsystem)有効化¶
5-1. audit 設定確認¶
5-2. 監査対象設定¶
/etc/security/audit/config を編集:
主要設定:
start:
binmode = on
streammode = on
bin:
trail = /audit/trail
bin1 = /audit/bin1
bin2 = /audit/bin2
binsize = 10240
cmds = /etc/security/audit/bincmds
freespace = 65536
stream:
cmds = /etc/security/audit/streamcmds
classes:
general = USER_SU,PASSWORD_Change,FILE_Unlink,FILE_Link,FILE_Rename,FS_Chdir,FS_Chroot,PORT_Locked,PORT_Change,FS_Mkdir,FS_Rmdir
objects = S_ENVIRON_WRITE,S_GROUP_WRITE,S_LIMITS_WRITE,S_LOGIN_WRITE,S_PASSWD_READ,S_PASSWD_WRITE,S_USER_WRITE,AUD_CONFIG_WR
SRC = SRC_Start,SRC_Stop,SRC_Addssys,SRC_Chssys,SRC_Delssys,SRC_Addserver,SRC_Chserver,SRC_Delserver
kernel = PROC_Create,PROC_Delete,PROC_Execute,PROC_RealUID,PROC_AuditID,PROC_RealGID,PROC_Environ,PROC_SetSignal,PROC_Limits,PROC_SetPri,PROC_Setpri,PROC_Privilege,PROC_Settimer
files = FILE_Open,FILE_Read,FILE_Write,FILE_Close,FILE_Link,FILE_Unlink,FILE_Rename,FILE_Owner,FILE_Mode,FILE_Acl,FILE_Privilege,DEV_Create,FILE_Symlink
users:
root = general,objects,SRC,kernel,files
default = general
5-3. 出力 FS 用意¶
# 監査ログ用 FS 作成(IBM Security マニュアルで /audit を別 FS として記載)
mklv -y auditlv -t jfs2 datavg 100 # 6.4GB
crfs -v jfs2 -d auditlv -m /audit -A yes -p rw -a logname=INLINE
mount /audit
chown root:audit /audit
chmod 750 /audit
5-4. audit 起動¶
# 一度起動
audit start
# 自動起動(/etc/rc 等に追加)
echo 'audit start' >> /etc/rc
# 状態確認
audit query
ls -la /audit/
期待出力:
# audit query
auditing on
audit bin manager is process 12345
audit events:
general
objects
SRC
kernel
files
audit objects:
... (略)
# ls -la /audit/
-rw------- 1 root audit 12345 May 04 12:00 bin1
-rw------- 1 root audit 0 May 04 12:00 bin2
-rw------- 1 root audit 54321 May 04 12:00 trail
5-5. 監査レポート生成¶
# 全監査ログを人間可読形式で
auditpr -v < /audit/trail | head -50
# 特定ユーザの操作のみ
auditpr -v < /audit/trail | awk '/^USER_SU/'
# 時間帯絞り込み
auditselect -e "time >= 09:00:00 and time <= 10:00:00 and command == passwd" /audit/trail | auditpr -v
Step 6: 運用・棚卸し体制¶
6-1. 定期棚卸しスクリプト¶
#!/usr/bin/ksh
# /usr/local/bin/user_audit.sh
# 月次棚卸し用
REPORT=/tmp/user_audit_$(date +%Y%m).txt
{
echo "=== AIX User Audit Report ==="
echo "Generated: $(date)"
echo "Host: $(hostname)"
echo
echo "=== sales2 Group Members ==="
lsgroup -a users sales2
echo
echo "=== Users with last login > 90 days ago ==="
for u in $(lsgroup -a users sales2 | awk -F= '{print $2}' | tr ',' ' '); do
last_login=$(lsuser -a time_last_login $u 2>/dev/null | awk '{print $2}' | cut -d= -f2)
if [ -n "$last_login" ] && [ $last_login -lt $(($(date +%s) - 7776000)) ]; then
echo "$u (last_login=$(perl -e 'print scalar localtime('$last_login'), "\n"'))"
fi
done
echo
echo "=== Locked accounts ==="
for u in $(lsgroup -a users sales2 | awk -F= '{print $2}' | tr ',' ' '); do
locked=$(lsuser -a account_locked $u 2>/dev/null | awk '{print $2}' | cut -d= -f2)
retries=$(lsuser -a unsuccessful_login_count $u 2>/dev/null | awk '{print $2}' | cut -d= -f2)
if [ "$locked" = "true" ] || [ "$retries" -ge 5 ]; then
echo "$u: account_locked=$locked unsuccessful_login_count=$retries"
fi
done
} > $REPORT
cat $REPORT
mailx -s "AIX User Audit $(hostname) $(date +%Y%m)" admin@example.com < $REPORT
6-2. cron 登録¶
追加:
6-3. 退職者対応プロセス¶
退職通知を受けたら:
USER=resigned-user
# ロック
chuser account_locked=true $USER
# パスワード即時失効
pwdadm -f ADMCHG $USER
# 30 日後に削除(home ファイル含む)
echo "rmuser -p $USER && rm -rf /home/$USER" | at now + 30 days
よくあるトラブル¶
トラブル 1: mkuser で 3004-687 Group does not exist¶
原因: pgrp 指定したグループ未作成
対処: mkgroup で先に作成
トラブル 2: home ディレクトリが root 所有のまま¶
原因: mkuser のオプション組み合わせ、または -m オプション忘れ
対処: 後から chown $u:sales2 /home/$u
トラブル 3: passwd が Permission denied¶
原因: /etc/security/passwd の権限破損
対処: chmod 600 /etc/security/passwd && chown root:security /etc/security/passwd
トラブル 4: audit start で Audit subsystem already running¶
原因: 既に起動済
対処: audit shutdown → audit start
トラブル 5: /audit FS が満杯¶
原因: rotate 設定不足、または大量イベント
対処:
- freespace を大きく
- 古い trail を別ストレージへ移動
- bincmds で rotate スクリプト実装
トラブル 6: ユーザがログインできない(logintimes 制限)¶
原因: logintimes 設定で許可時間外
対処: chuser logintimes="" $u で一時解除、または許可時間調整
トラブル 7: 一括追加スクリプトで lsuser が遅い¶
原因: LDAP 統合でネットワーク確認が走る
対処: ローカル files registry のみ使う(lsuser -R files)
関連エントリ¶
コマンド¶
lsuser,mkuser,chuser,rmuserlsgroup,mkgroup,chgroup,rmgrouppasswd,pwdadm,chsecaudit,auditpr,auditselect
用語¶
設定値¶
- /etc/security/user, /etc/security/group, /etc/security/passwd, /etc/security/login.cfg, /etc/security/limits(02-settings.md)
- /etc/security/audit/config
設定手順¶
- cfg-user-add - 個別ユーザ追加(カタログ版)
- cfg-passwd-policy - ロック解除
障害対応¶
本記事の範囲¶
本記事は IBM AIX 7.3 公式マニュアル(AIX 7.3 Commands Reference, Operating system management, Networking, Performance management, Security, Logical Volume Manager (LVM), JFS2 file system)に記載された事実・手順のみで構成しています。
本記事の 範囲外:
- 「現場でのベストプラクティス」「経験的な判断基準」「運用ノウハウ」等の定性的情報
- 性能チューニングの推奨閾値(環境依存のため)
- 業務影響評価の判断基準(組織のリスク許容度依存)
- アンチパターン・落とし穴の主観的列挙
- ツール選定の優劣評価
これらは経験ある SME(Subject Matter Expert)または IBM サポートにご確認ください。本記事に「期待出力」として記載しているコマンド出力は、AIX 7.3 公式マニュアル記載例または man <command> の出力例を参照しており、実機環境ではバージョン・設定によって差異が生じる可能性があります。
特集 5: TCP/IP 設定変更から検証・運用反映まで¶
重要度: S / カテゴリ: ネットワーク
概要: ネットワークセグメント変更(VLAN 移動・IP 帯変更)の本番系作業。事前準備から ifconfig 変更、ルーティング、DNS 更新、関連サーバ通知、業務確認まで。
シナリオ¶
ネットワーク部門から通知:
セグメント再編で AIX サーバを VLAN 100 → VLAN 200 に移動する。 IP も 192.168.10.x/24 → 192.168.20.x/24 に変更。 来週末のメンテナンス枠で実施してほしい。 関連: DNS 更新、PowerHA クラスタへの影響、業務側 connection string 変更が必要。
この特集記事は、AIX 管理者が 「事前計画 → メンテ前準備 → IP/ルーティング変更 → 動作検証 → 運用反映 → 関連系への通知」 まで包括的に進める実例。
Step 0: 事前計画(メンテナンス 1-2 週間前)¶
0-1. 現状の把握¶
# 全 NIC の状態
lsdev -Cc adapter | grep -E "ent|en"
ifconfig -a
# IP・ルーティング
netstat -rn
# DNS 設定
cat /etc/resolv.conf
# VLAN 構成(VLAN tagging 使用時)
entstat -d en0 | head -30
期待出力:
# ifconfig -a
en0: flags=1e084863,1c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),CHAIN>
inet 192.168.10.10 netmask 0xffffff00 broadcast 192.168.10.255
# netstat -rn
default 192.168.10.1 UG 1 1234 en0 -
192.168.10/24 192.168.10.10 U 1 5678 en0 -
0-2. 変更後設計の確定¶
| 項目 | 現在 | 変更後 |
|---|---|---|
| IP | 192.168.10.10 | 192.168.20.10 |
| Default GW | 192.168.10.1 | 192.168.20.1 |
| FQDN | my-server.example.com | 変更なし |
0-3. 関連系への影響確認・通知¶
事前通知すべき関連: - DNS 管理者 → A/PTR レコード変更依頼 - アプリ DB clients → connection string 確認依頼 - PowerHA 構成 → クラスタ管理者と協議 - 監視サーバ → 監視対象 IP 変更依頼 - firewall ルール → 新 IP 許可ルール追加依頼
Step 1: メンテナンス当日(事前準備)¶
1-1. nologin 配置¶
1-2. mksysb 取得¶
1-3. 設定ファイルバックアップ¶
mkdir -p /backup/etc_pre_ipchange_$(date +%Y%m%d)
cp -p /etc/hosts /etc/resolv.conf /etc/netsvc.conf /backup/etc_pre_ipchange_$(date +%Y%m%d)/
lsattr -El inet0 > /backup/etc_pre_ipchange_$(date +%Y%m%d)/lsattr_inet0.txt
lsattr -El en0 > /backup/etc_pre_ipchange_$(date +%Y%m%d)/lsattr_en0.txt
Step 2: IP 変更(コンソール接続から実行)¶
2-1. 旧設定解除¶
chdev -l inet0 -a delroute=net,-hopcount,0,0,0,0.0.0.0,192.168.10.1
ifconfig en0 down
chdev -l en0 -a netaddr=0.0.0.0
2-2. 新 IP 設定(永続)¶
期待出力:
en0: flags=1e084863,1c0<UP,BROADCAST,RUNNING,...>
inet 192.168.20.10 netmask 0xffffff00 broadcast 192.168.20.255
2-3. デフォルトルート設定¶
2-4. /etc/hosts 更新¶
2-5. /etc/resolv.conf 更新(必要なら)¶
Step 3: 検証¶
3-1. 基本疎通¶
ping -c 4 192.168.20.1 # GW
ping -c 4 my-server.example.com # 自ホスト
nslookup my-server.example.com # DNS 解決
nslookup www.ibm.com # 外部 DNS
3-2. ssh アクセス再開確認¶
別端末から:
3-3. 関連サービス確認¶
lssrc -a | grep -v inoperative
# NFS マウント再確認
mount | grep nfs
df -g | grep nfs
# 必要なら remount
umount -f /mnt/nfsdata
mount /mnt/nfsdata
3-4. アプリ動作確認¶
業務側に依頼: - DB 接続テスト - アプリログイン - バッチジョブ起動
Step 4: 運用反映¶
4-1. nologin 削除¶
4-2. 関連系への完了通知¶
TO: NW管理者、DNS管理者、業務部門、監視管理者
RE: my-server IP 変更完了
[変更内容] 192.168.10.10 → 192.168.20.10
[FQDN] 変更なし
[結果] 疎通 OK、業務再開可能
[対応依頼]
- DNS: A/PTR レコード新 IP 反映確認
- 監視: 対象 IP 更新確認
- 業務: アプリ動作確認
- NW: firewall 新 IP 許可確認
4-3. PowerHA クラスタ更新(HACMP 環境のみ)¶
clmgr stop cluster
clmgr modify network <network> -a service_address=192.168.20.10
clmgr sync cluster
clmgr start cluster
clRGinfo
4-4. ドキュメント更新¶
CMDB / 構成管理ドキュメントを最新化(IP 一覧、VLAN 配置表、ネットワーク図)。
Step 5: rollback(必要時)¶
ssh でも到達不可、業務動作不能等の重大問題発生時:
5-1. 設定ファイル復元¶
cp /backup/etc_pre_ipchange_*/hosts /etc/hosts
cp /backup/etc_pre_ipchange_*/resolv.conf /etc/resolv.conf
5-2. 旧 IP に戻す(コンソールから)¶
ifconfig en0 down
chdev -l en0 -a netaddr=192.168.10.10 -a netmask=255.255.255.0
ifconfig en0 up
chdev -l inet0 -a delroute=net,-hopcount,0,0,0,0.0.0.0,192.168.20.1
chdev -l inet0 -a route=net,-hopcount,0,0,0,0.0.0.0,192.168.10.1
5-3. NW 機器側も旧 VLAN/セグメントに戻す依頼¶
NW 管理者に rollback 通知。物理的な VLAN 配置も戻す必要があれば実施。
5-4. 復旧確認¶
よくあるトラブル¶
トラブル 1: chdev で 0514-040 Error initializing a device into the kernel¶
原因: en0 が他プロセスで使用中、または NFS マウント中
対処: umount -af で全マウント解除、または -P で次回 boot 反映に切り替え
トラブル 2: SSH で再接続できない¶
原因: 1) NW 機器側の ARP 未更新、2) firewall ブロック、3) 物理ケーブル
対処: 別ホストから新 IP ping、entstat -d en0 で送受信統計確認、NW 管理者に依頼
トラブル 3: nslookup が timeout¶
原因: 新 DNS サーバへの 53/udp 不通
対処: ping <dns-server> 確認、/etc/resolv.conf 再確認
トラブル 4: 既存 NFS マウントが Stale¶
原因: NFS サーバ側の export で旧 IP/FQDN を許可
対処: NFS サーバ側で /etc/exports 新 IP に更新後 exportfs -av、AIX 側で umount -f → mount
トラブル 5: PowerHA クラスタが split-brain¶
原因: クラスタ間 heartbeat が片肺
対処: クラスタ片側強制停止、設定再同期、ベンダーサポート相談
トラブル 6: アプリが旧 IP で hardcode¶
原因: アプリ設定ファイル / DB connection string で IP 直書き
対処: 業務側に設定変更依頼。または ifconfig en0 alias <旧 IP> で旧 IP も応答するよう設定(NW 機器側のルーティングが新セグメント向きの場合は到達不可)
トラブル 7: DNS の TTL 長くて古い IP がキャッシュされている¶
原因: DNS レコードの TTL(既定 86400 秒等)
対処: 事前に TTL 短縮(300 秒等)、クライアント側 nscd キャッシュクリア
関連エントリ¶
コマンド¶
用語¶
設定値¶
- /etc/hosts, /etc/resolv.conf, /etc/netsvc.conf, /etc/rc.tcpip
- tcp_sendspace, tcp_recvspace, sb_max(02-settings.md)
設定手順¶
障害対応¶
本記事の範囲¶
本記事は IBM AIX 7.3 公式マニュアル(AIX 7.3 Commands Reference, Operating system management, Networking, Performance management, Security, Logical Volume Manager (LVM), JFS2 file system)に記載された事実・手順のみで構成しています。
本記事の 範囲外:
- 「現場でのベストプラクティス」「経験的な判断基準」「運用ノウハウ」等の定性的情報
- 性能チューニングの推奨閾値(環境依存のため)
- 業務影響評価の判断基準(組織のリスク許容度依存)
- アンチパターン・落とし穴の主観的列挙
- ツール選定の優劣評価
これらは経験ある SME(Subject Matter Expert)または IBM サポートにご確認ください。本記事に「期待出力」として記載しているコマンド出力は、AIX 7.3 公式マニュアル記載例または man <command> の出力例を参照しており、実機環境ではバージョン・設定によって差異が生じる可能性があります。
v10 補足: OpenSSH / OpenSSL バージョン整合表(AIX 7.3 TL/SP 別)¶
AIX 7.3 では OpenSSL 1.0 系列から 3.0 系列への移行があり、TL/SP に応じてバンドルされる OpenSSH/OpenSSL のバージョンが異なります。実機の TL/SP は oslevel -s で確認 し、本表で対応バージョンを照合してください。
| AIX TL/SP | OpenSSL | OpenSSH | 注記 |
|---|---|---|---|
| AIX 7.3 TL3 SP1 (2024-12) | 3.0.15.1001 | 10.0.0.x ベース | OpenSSL 3.0.x 系列。FIPS モード対応 |
| AIX 7.3 TL3 SP0 (2024-08) | 3.0.14.x | 9.x | TL3 一般リリース |
| AIX 7.3 TL2 SP1 (2024-05) | 3.0.13.x | 9.x | OpenSSL 3.0 標準化 |
| AIX 7.3 TL1 SP1 (2023) | 1.0.2.x(互換) | 8.x | OpenSSL 1.0 系列の最終版(移行推奨) |
注意: AIX 7.3 では OpenSSL 1.0 → 3.0 への移行があるため、TL/SP に応じて openssl version と ssh -V を必ず確認。古い .cnf(openssl.cnf)を退避してから アップグレード。アプリ側で EVP_* API を使っているとリビルドが必要なケースあり。詳細は IBM AIX Web Download Pack ページを参照(リンクは上記 URL)。
出典: IBM AIX Web Download Pack — Downloading and installing or upgrading OpenSSL and OpenSSH https://www.ibm.com/support/pages/downloading-and-installing-or-upgrading-openssl-and-openssh
v10 補足: Trusted Execution 公式マニュアルリンク補強¶
Trusted Execution(TE)は AIX 7.3 の Security 章で扱われる定番機能ですが、v9 では本文中の言及のみで、各 policy の公式リンクが不足していました。v10 で公式マニュアルの該当ページへの直接リンクを補強します。
| 項目 | 公式マニュアル | 備考 |
|---|---|---|
| Trusted Execution overview | https://www.ibm.com/docs/en/aix/7.3?topic=trusted-execution-overview | AIX 7.3 公式 Security ガイド内 Trusted Execution 概要 |
| trustchk command reference | https://www.ibm.com/docs/en/aix/7.3?topic=t-trustchk-command | TSD(Trusted Signature Database)操作コマンド |
| CHKEXEC / CHKSHLIB / CHKSCRIPT / CHKKERNEXT | https://www.ibm.com/docs/en/aix/7.3?topic=execution-trusted-policies | Trusted Execution の各 policy(実行ファイル / 共有ライブラリ / スクリプト / カーネル拡張) |
| STOP_ON_CHKFAIL / STOP_UNTRUSTED policy | https://www.ibm.com/docs/en/aix/7.3?topic=execution-trusted-policies | policy 違反時の挙動制御(block / log only) |
| AIX Trusted Execution と AIX Pert(Security Expert)の関係 | https://www.ibm.com/docs/en/aix/7.3?topic=command-aixpert | AIXPert で Trusted Execution policy をテンプレート適用可能 |
運用上の注意
Trusted Execution の policy で STOP_ON_CHKFAIL=ON を有効化すると、 TSD(Trusted Signature Database)に登録されていない実行ファイルが即座に block されます。 本番環境で有効化する前に、trustchk -y CHKEXEC=ON の log only モードで影響範囲を必ず確認してください。