設定手順¶
掲載:18 件(S 級 13 + A 級 5 が詳細版、B/C 級は概要版)(定番のみ)。除外項目は 10. 対象外項目 を参照。
v9 から: 重要度 S 級 13 件 + A 級 5 件が詳細版(100-200 行)。B/C 級は概要版。
重要度 × 用途 マトリクス¶
| 重要度\用途 | ストレージFS | ネットワーク | バックアップ | パッケージ | ユーザ認証 | ログ監査 | 性能 |
|---|---|---|---|---|---|---|---|
| S | cfg-nfs-mount cfg-vg-lv cfg-rootvg-mirror cfg-fs-extend cfg-disk-add |
cfg-hostname-ip cfg-dns cfg-ntp |
cfg-mksysb-backup | cfg-package-install | cfg-user-add cfg-passwd-policy |
cfg-syslog | — |
| A | — | — | — | — | — | cfg-errnotify cfg-dump-device |
cfg-mpio-tuning cfg-tcp-buffers cfg-ioo-tuning |
| B | — | — | — | — | — | — | — |
| C | — | — | — | — | — | — | — |
詳細手順¶
cfg-hostname-ip: ホスト名と IP アドレスの変更¶
重要度: S 級詳細版 / 用途: ネットワーク
目的¶
AIX システムのホスト名と IP アドレスを永続的に変更する。
業務シナリオ: - データセンタ移行・統合に伴う IP セグメント変更 - 命名規則変更(例: srv001 → web-prod-tokyo-01) - 開発機をテスト環境/本番環境へ昇格させる際の名前変更 - LPAR の HMC マイグレーション後の再ネーミング
影響範囲: 既存 SSH 接続は切れる。NFS マウント先からは hostname/IP 解決が失敗する可能性。 HACMP/PowerHA クラスタメンバの場合は事前にクラスタ管理者と調整必須。
前提条件¶
- root 権限(または RBAC で
aix.system.config.network認可保有) - 対象 NIC(en0 等)が cfgmgr で
Available状態 - 新 IP の重複チェック済み(
ping -c 4 <new_ip>で応答無し確認) - DNS 管理者・上位ネットワーク機器側との変更同期準備
- /etc/hosts 編集権限
- 本番系の場合: 切替時間帯の調整、関連サービス(DB・ジョブスケジューラ等)の停止計画
- バックアップ取得済(最低限
/etc/hosts,/etc/resolv.conf,lsattr -El inet0,lsattr -El en0の出力を保存)
手順¶
Step 1: 現状確認とバックアップ取得¶
コマンド:
# 現在のホスト名
hostname
# 現在の IP・ネットマスク・ブロードキャスト
ifconfig en0
# inet0 の hostname 属性
lsattr -El inet0 -a hostname
# ネットワーク関連の ODM 属性
lsattr -El en0
# /etc/hosts のバックアップ
cp /etc/hosts /etc/hosts.bak.$(date +%Y%m%d)
# /etc/resolv.conf のバックアップ
cp /etc/resolv.conf /etc/resolv.conf.bak.$(date +%Y%m%d)
期待される出力:
# hostname
old-server.example.com
# ifconfig en0
en0: flags=1e084863,1c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),CHAIN>
inet 192.168.10.10 netmask 0xffffff00 broadcast 192.168.10.255
tcp_sendspace 262144 tcp_recvspace 262144 rfc1323 1
# lsattr -El inet0 -a hostname
hostname old-server.example.com Host Name True
注意点:
- 重要: 現状値は必ずメモまたはファイル保存。rollback 時に必要。
ifconfigのflagsにUP,RUNNINGが含まれていない場合は NIC が物理 down している可能性。- MPIO/EtherChannel 等で複数 NIC を束ねている場合は
lsdev -Cc adapter | grep entで全 NIC を確認。
Step 2: ホスト名の永続変更¶
コマンド:
# inet0 属性で hostname を変更(永続)
chdev -l inet0 -a hostname=new-server.example.com
# /etc/hosts に新エントリを追記(vi で編集)
vi /etc/hosts
# 追記内容例:
# 192.168.10.20 new-server.example.com new-server
期待される出力:
注意点:
- FQDN(hostname.domain)で指定すると
hostnameコマンド出力もそうなる。短い名前のみならnew-serverだけ。 - /etc/hosts は TAB 区切り推奨(スペースでも動作するが見栄えのため)。
- loopback 行
127.0.0.1 loopback localhostは絶対に消さない(消すと多くのデーモンが死ぬ)。
Step 3: IP アドレス・ネットマスクの永続変更¶
コマンド:
# en0 の IP・netmask を変更(永続)
chdev -l en0 -a netaddr=192.168.10.20 -a netmask=255.255.255.0
# 必要なら gateway も
chdev -l inet0 -a route=net,-hopcount,0,0,0,0.0.0.0,192.168.10.1
期待される出力:
注意点:
- chdev は即時反映。実行した瞬間に SSH セッションが切れる可能性が高い。コンソール接続から実行が安全。
- 切れた SSH から再接続する場合は新 IP に対して接続。
- EtherChannel 構成の場合は
chdev -l ent_aggr -a ...のように aggregation device 側を変更。 - VLAN tag 付きインターフェース(en1.100 等)は別コマンド体系。
Step 4: DNS 設定の更新(必要に応じて)¶
コマンド:
期待される出力:
# 編集後の内容例:
domain example.com
search example.com sub.example.com
nameserver 192.168.10.1
nameserver 192.168.10.2
# nslookup で動作確認
nslookup new-server.example.com
注意点:
- 新 IP が DNS サーバに登録されていなければ正引き失敗するが、これは OS の責任ではない。
/etc/netsvc.confのhosts=local,bindで local(hosts ファイル)優先指定があれば DNS 未登録でも動く。
Step 5: 新 IP / hostname の動作確認¶
コマンド:
# ホスト名確認
hostname
# 新 IP の確認
ifconfig en0
# ループバック解決
ping -c 2 new-server.example.com
# 自分から自分への ssh
ssh root@new-server.example.com hostname
期待される出力:
# hostname
new-server.example.com
# ifconfig en0
en0: flags=...
inet 192.168.10.20 netmask 0xffffff00 broadcast 192.168.10.255
# ping -c 2 new-server.example.com
PING new-server.example.com (192.168.10.20): 56 data bytes
64 bytes from 192.168.10.20: icmp_seq=0 ttl=255 time=0.041 ms
64 bytes from 192.168.10.20: icmp_seq=1 ttl=255 time=0.034 ms
注意点:
- ssh が known_hosts エラーで失敗する場合は
ssh-keygen -R old-server.example.comで旧エントリ削除後に再試行。 - 外部から到達できるかは別マシンから ping して確認すること(自分自身の loopback テストだけでは不十分)。
検証¶
チェックリスト(全て OK で完了):
- [ ]
hostnameが新名前を返す - [ ]
ifconfig en0のinet行が新 IP・新 netmask - [ ] 別ホストから
ping new-server.example.comで応答あり - [ ] 別ホストから
ssh root@new-server.example.comで接続成功 - [ ] 関連業務アプリ(DB クライアント、Web、ジョブ)から接続テスト成功
- [ ] HACMP/PowerHA 構成の場合、クラスタコマンド
clmgrで構成更新成功 - [ ]
lsattr -El inet0 -a hostnameで新 hostname、lsattr -El en0 -a netaddrで新 IP
追加検証(重要システム): - アプリログに connection refused / DNS 解決失敗エラーが出ていないか 24h 監視 - 監視サーバ(Nagios, Zabbix, Tivoli 等)の対象ホスト名/IP も更新
ロールバック¶
全 step を逆順で巻き戻す。コンソール接続から実施推奨(SSH 切断のリスク)。
-
/etc/hosts.bak.YYYYMMDD で復元:
-
/etc/resolv.conf も同様に復元:
-
旧 IP に戻す:
-
旧 hostname に戻す:
-
上記で SSH 切断されたら、コンソールから新たに接続(旧 IP 192.168.10.10)。
最終手段: rebootすれば次回起動時 ODM の値で立ち上がるので、変更失敗時は shutdown -Fr now も視野に。
注意: chdev -P で次回 boot 反映を選択していた場合は、reboot 必要。
関連エントリ¶
- 用語: TCP/IP, ODM
- コマンド:
hostname,ifconfig,chdev,lsattr - 設定: /etc/hosts, /etc/resolv.conf
- 関連手順: cfg-dns, cfg-ntp, inc-network-down
典型的な障害パターン¶
症状: chdev で Method error (/etc/methods/chginet) : 0514-068
- 原因: inet0 が他のプロセスで使用中(NFS マウント中等)
- 対処: マウント解除(
umount -af)→ chdev 再試行。または -P で次回 boot 反映に。
症状: ssh が Connection timed out になる
- 原因: 上位ネットワーク機器(router/switch)のルーティング/ARP テーブル未更新、または firewall ブロック
- 対処: 新 IP の MAC アドレス通知(
arpingまたはping -b broadcast)。firewall ルール追加。
症状: hostname が新名前を返さない
- 原因: chdev 失敗または別プロセスが /etc/hosts を保持
- 対処: 再 chdev、または
hostname new-server.example.com(一時的)の後に再 boot で永続化確認。
症状: /etc/hosts への vi 編集後 mount /home が Stale file handle
- 原因: NFS サーバ側で旧 IP/hostname を export していた
- 対処: NFS サーバ側で
/etc/exportsを新名前に更新後exportfs -av。
出典: S_AIX73_network
cfg-dns: DNS リゾルバ設定(/etc/resolv.conf)¶
重要度: S 級詳細版 / 用途: ネットワーク
目的¶
AIX を DNS クライアントとして設定する。
業務シナリオ: - 新規構築 LPAR の初期セットアップ - 社内 DNS サーバ(Active Directory DC や BIND サーバ)への参照追加 - DNS サーバ移設・追加・削除に伴う設定更新 - マルチドメイン環境での search リスト追加
影響範囲: 設定変更後に起動するプロセスから新設定が適用される。 既存接続は影響なし、ただし socket 開きっぱなしのアプリは旧設定のまま継続。
前提条件¶
- root 権限
- 上位 DNS サーバの IP アドレスが分かっていること(53/udp 53/tcp 疎通可能)
- DNS サーバ側に AIX クライアント用の forward/reverse レコード登録済(推奨)
- /etc/hosts でバックアップ解決可能であること(推奨)
手順¶
Step 1: 現状確認とバックアップ¶
コマンド:
# 現在の resolv.conf
cat /etc/resolv.conf
# 現在の検索順序
cat /etc/netsvc.conf
# バックアップ
cp /etc/resolv.conf /etc/resolv.conf.bak.$(date +%Y%m%d)
cp /etc/netsvc.conf /etc/netsvc.conf.bak.$(date +%Y%m%d)
期待される出力:
注意点:
- /etc/netsvc.conf がない場合は
hosts=local,bindがデフォルト。 - /etc/resolv.conf がない場合 DNS は無効、/etc/hosts のみで名前解決。
Step 2: /etc/resolv.conf を作成・編集¶
コマンド:
期待される出力:
# 編集内容例:
domain example.com
search example.com sub.example.com tokyo.example.com
nameserver 192.168.10.1
nameserver 192.168.10.2
options timeout:2 attempts:2
注意点:
domainは自分のドメイン名。searchは短い名前で検索したときの補完候補(複数記述可)。nameserverは最大 3 つまで(4つ目以降は無視)。上から順に試行される。options timeout:2 attempts:2で各サーバへの再試行間隔と回数を調整(既定はそれぞれ 5 と 2)。- スペルミスに注意:
namesever等のタイポでも沈黙して失敗する。
Step 3: /etc/netsvc.conf で参照順序を制御¶
コマンド:
期待される出力:
# 編集内容例(local → bind の順、推奨):
hosts=local,bind
# AD 統合環境なら:
hosts=local,bind4,bind6
# DNS のみ:
hosts=bind
注意点:
- Linux の /etc/nsswitch.conf 相当。
local= /etc/hosts、bind= DNS。- 順序を逆にすると(
hosts=bind,local)DNS 優先。多数のホスト名解決時に DNS 負荷増。
Step 4: 即時反映確認¶
コマンド:
# 名前解決テスト
nslookup www.ibm.com
host www.ibm.com
# 検索リスト動作確認(短い名前)
nslookup gw
# /etc/hosts 経由解決
nslookup loopback
# DNS サーバ別に明示テスト
nslookup www.ibm.com 192.168.10.1
期待される出力:
# nslookup www.ibm.com
Server: 192.168.10.1
Address: 192.168.10.1#53
Non-authoritative answer:
Name: www.ibm.com
Address: 23.51.144.94
# host www.ibm.com
www.ibm.com has address 23.51.144.94
注意点:
nslookupは標準で対話モードに入るので、引数指定で 1 回問い合わせ。bind.rte導入済ならdigも使える(より詳細な情報表示)。- 解決失敗の場合
;; connection timed out; no servers could be reached等のメッセージ。
検証¶
チェックリスト:
- [ ]
nslookup <既知の外部ホスト>で正引き成功 - [ ]
nslookup <既知の IP>で逆引き成功(PTR レコード設定済の場合) - [ ]
host <短い名前>で search リスト経由の補完成功 - [ ] /etc/hosts に登録された名前 → local 解決成功(netsvc.conf=local,bind 時)
- [ ] DNS サーバを順に切ってもタイムアウト後に次のサーバへフォールバック
- [ ] アプリ(DB connect 等)から FQDN 指定で接続成功
長期検証: - DNS サーバの 1 台メンテ時に他のサーバで継続動作することを実機切替で確認 - 24h 後にアプリログに DNS 関連エラーが累積していないか確認
ロールバック¶
-
バックアップから復元:
-
設定を完全に無効化したい場合(local のみで運用):
-
動作確認:
-
DNS 解決を完全に止めるリスク: アプリが FQDN ハードコードしている場合は止まる。事前に /etc/hosts への必須エントリ追加推奨。
関連エントリ¶
- 用語: BIND 9.18, TCP/IP
- コマンド:
nslookup,host,dig - 設定: /etc/resolv.conf, /etc/netsvc.conf, /etc/hosts
- 関連手順: cfg-hostname-ip, inc-network-down
典型的な障害パターン¶
症状: nslookup で ;; connection timed out
- 原因: DNS サーバへの 53/udp 疎通不可、または DNS サーバダウン
- 対処:
ping <dns_server>で疎通確認、telnet <dns_server> 53で TCP 疎通確認、firewall 確認
症状: 短い名前(gw 等)で解決できない
- 原因: /etc/resolv.conf に
search行がない、または domain 補完が効いていない - 対処: search 行に対象ドメインを追加
症状: 解決はできるが応答が異常に遅い(数秒〜十数秒)
- 原因: 1 番目の DNS サーバが応答しないため timeout 後に 2 番目に切り替わっている
- 対処: DNS サーバ順序を見直す、
options timeout:1 attempts:1で短縮
症状: nslookup は通るが ping は通らない
- 原因: DNS は OK だが ICMP がブロックされている(または逆引きで遅延)
- 対処:
ping -nで逆引き抑止、firewall ICMP ルール確認
出典: S_AIX73_network
cfg-nfs-mount: NFS マウントの設定¶
重要度: S 級詳細版 / 用途: ストレージFS
目的¶
リモート NFS サーバの export を AIX クライアントにマウントする。
業務シナリオ: - 共有ファイルストレージへのアクセス(ホームディレクトリ・配布バイナリ・ログ集約等) - AIX 同士のファイル共有(PowerHA クラスタの設定ファイル共有等) - バックアップ先 NAS のマウント - インストールメディアの一時マウント(NIM サーバ経由インストール等)
前提条件¶
- root 権限
- NFS サーバが起動済み・対象 FS が export 済み
- bos.net.nfs.client fileset インストール済(
lslpp -L bos.net.nfs.clientで確認) - NFS サーバまでの 2049/tcp(NFSv4)または 2049/udp+portmapper 関連ポート疎通可能
- AIX 7.3.1 以降では 16TB 超ファイル対応(古いクライアントでは 2GB 制限)
手順¶
Step 1: クライアント側 NFS デーモン起動確認¶
コマンド:
期待される出力:
# lssrc -g nfs
Subsystem Group PID Status
biod nfs 12340 active
nfsd nfs 12341 active
rpc.lockd nfs 12342 active
rpc.statd nfs 12343 active
rpc.mountd nfs 12344 active
注意点:
- クライアントとして使う最低限は
biodとrpc.statdrpc.lockd。 - サーバとして使う場合は
nfsdrpc.mountdrpc.statdrpc.lockdも必要。
Step 2: NFS サーバの export 確認¶
コマンド:
# サーバ側 export 一覧を取得
showmount -e <NFS server hostname or IP>
# 例:
showmount -e nfs-srv01.example.com
期待される出力:
# showmount -e nfs-srv01.example.com
export list for nfs-srv01.example.com:
/export/data (everyone)
/export/home 192.168.10.0/24
/export/binaries aix-clients
注意点:
- 対象 FS が一覧にない場合はサーバ側で export されていない。NFS サーバ管理者に依頼。
- アクセス制限が表示される(IP 範囲、ホスト名グループ等)。自分が許可されているか確認。
Step 3: マウントポイント作成と一時マウントテスト¶
コマンド:
# マウントポイント作成
mkdir -p /mnt/nfsdata
# 一時マウント(NFSv3)
mount -o vers=3,rw,bg,intr,timeo=600 nfs-srv01.example.com:/export/data /mnt/nfsdata
# または NFSv4
mount -o vers=4 nfs-srv01.example.com:/export/data /mnt/nfsdata
# マウント確認
mount | grep nfsdata
df -g /mnt/nfsdata
期待される出力:
# mount | grep nfsdata
nfs-srv01.example.com /export/data /mnt/nfsdata nfs3 May 04 10:35 rw,bg,intr,timeo=600
# df -g /mnt/nfsdata
Filesystem GB blocks Free %Used Mounted on
nfs-srv01.example.com:/export/data
100.00 45.32 55% /mnt/nfsdata
注意点:
- bg オプション: ネットワーク不通時にバックグラウンド再試行(プロンプトに戻る)。
- intr オプション: ハング時に Ctrl+C で中断可能(NFS hard mount のため)。
- vers=3 vs vers=4: 既存サーバが v3 限定なら vers=3。v4 はステートフルでファイヤウォール越えしやすい。
Step 4: 永続化(/etc/filesystems への登録)¶
コマンド:
# mknfsmnt で /etc/filesystems に登録
mknfsmnt -f /mnt/nfsdata \
-d /export/data \
-h nfs-srv01.example.com \
-A \
-m \
-t rw \
-B \
-I \
-X soft
# 登録内容確認
grep -A 8 nfsdata /etc/filesystems
期待される出力:
# grep -A 8 nfsdata /etc/filesystems
/mnt/nfsdata:
dev = "/export/data"
vfs = nfs
nodename = nfs-srv01.example.com
mount = true
options = bg,intr,rw,soft,timeo=600
account = false
注意点:
- オプション意味:
-A=自動マウント、-m=マウント、-t rw=読み書き、-B=bg、-I=intr、-X soft=soft mount。 - hard vs soft: hard はサーバ復活まで待つ(業務系推奨)、soft はタイムアウトでエラーリターン(一時マウント等)。
Step 5: 動作確認¶
コマンド:
# unmount してから自動マウントテスト
umount /mnt/nfsdata
mount /mnt/nfsdata
# 確認
mount | grep nfsdata
ls -la /mnt/nfsdata
touch /mnt/nfsdata/test_$(hostname).txt
ls -la /mnt/nfsdata/test_$(hostname).txt
rm /mnt/nfsdata/test_$(hostname).txt
期待される出力:
# touch /mnt/nfsdata/test_my-server.txt
(エラーなく実行)
# ls -la /mnt/nfsdata/test_my-server.txt
-rw-r--r-- 1 root system 0 May 04 10:38 /mnt/nfsdata/test_my-server.txt
注意点:
- 書き込みエラー(Permission denied)の場合: NFS サーバ側 export オプションで
rwかno_root_squash設定確認。 - root_squash 既定: NFS サーバ側で root を匿名ユーザに変換するセキュリティ機能。Storage 側設定変更必要。
検証¶
チェックリスト:
- [ ]
mount出力にマウント済表示 - [ ]
df -g /mnt/nfsdataで容量表示 - [ ]
ls /mnt/nfsdataでファイル/サブディレクトリ表示 - [ ] rw マウントなら
touch /mnt/nfsdata/test.txt成功 - [ ]
umount /mnt/nfsdata && mount /mnt/nfsdataで永続マウント動作 - [ ] reboot 後の自動マウント確認(A=true 設定済の場合)
- [ ] アプリ(DB データファイル等)から NFS 上ファイルへの read/write 成功
長期検証:
- NFS サーバ側を再起動しても hard mount で復旧することを実機テスト
- 大量小ファイル read 性能(time ls -lR /mnt/nfsdata > /dev/null)が許容範囲
ロールバック¶
-
アクセス中プロセスの停止確認:
-
unmount:
-
永続化エントリ削除:
-
マウントポイントディレクトリ削除(必要なら):
-
確認:
hung mount で umount 失敗時:
関連エントリ¶
- 用語: NFS
- コマンド:
mount,umount,showmount,lssrc,startsrc,fuser,nfso - 設定: /etc/filesystems, /etc/exports(サーバ側)
- 関連手順: cfg-dns, inc-nfs-stale
典型的な障害パターン¶
症状: showmount -e <server> で clnttcp_create: RPC: Program not registered
- 原因: サーバ側で NFS デーモン未起動、または rpcbind/portmap 未起動
- 対処: サーバ管理者に依頼(サーバで
lssrc -g nfs確認・startsrc -g nfs)
症状: mount が mount: 1831-008 giving up on: ...:/export/data ; vmount: Operation not permitted
- 原因: サーバ側 export で当該クライアント IP/ホスト名が許可されていない
- 対処: サーバ管理者に依頼(/etc/exports に該当ホスト追加 → exportfs -av)
症状: マウントできるが書き込みで Permission denied
- 原因: サーバ側で root_squash 設定または ro export
- 対処: サーバ側 export を rw 化、または no_root_squash オプション付与
症状: マウントが hung(応答なし)、Ctrl+C も効かない
- 原因: hard mount で intr オプションなし、サーバが応答しない
- 対処: 別ターミナルから
umount -f /mnt/nfsdata、必要なら -F
症状: reboot 後に自動マウントされない
- 原因: NFS サーバが boot 完了より遅い、または bg オプション無し
- 対処: /etc/filesystems の該当 stanza に
bgオプション追加、または mountd 起動順序調整
出典: S_AIX73_network
cfg-ntp: NTP 時刻同期(NTPv4)¶
重要度: S 級詳細版 / 用途: ネットワーク
目的¶
NTPv4 サーバと時刻同期する。
業務シナリオ: - HACMP/PowerHA クラスタメンバ間の時刻ズレ防止(heartbeat 異常検知の前提) - ログ突合(複数サーバのアプリログを時刻順に並べる) - Kerberos 認証(時刻ズレ 5 分超で認証失敗) - 業務トランザクションのタイムスタンプ整合性 - バックアップジョブ・cron の正確な実行時刻保証
重要: AIX 7.3 で NTPv4(ntpd4)が既定。NTPv3(xntpd)は提供継続だが推奨されない。
前提条件¶
- root 権限
- NTP サーバが疎通可能(123/udp で外部 NTP サーバ、または社内 NTP サーバ)
- システム時刻が NTP サーバから極端にズレていないこと(数分以内推奨)。
- 大幅にズレている場合は事前に手動
ntpdate -u <ntp-server>で同期しておく - bos.net.tcp.client / bos.net.tcp.server fileset インストール済
手順¶
Step 1: 現状確認¶
コマンド:
# 現在の時刻
date
# UTC 時刻
date -u
# 現在の NTP デーモン状態
lssrc -s xntpd
# 既存設定ファイル確認
cat /etc/ntp.conf
# バックアップ
cp /etc/ntp.conf /etc/ntp.conf.bak.$(date +%Y%m%d)
期待される出力:
# date
Mon May 4 10:30:00 JST 2026
# lssrc -s xntpd
Subsystem Group PID Status
xntpd tcpip inoperative
# cat /etc/ntp.conf
broadcastclient
driftfile /etc/ntp.drift
tracefile /etc/ntp.trace
注意点:
Status: inoperative= NTP デーモン未起動。- デフォルトの ntp.conf は broadcastclient(マルチキャスト受信)になっており、明示 server 指定なし。
Step 2: /etc/ntp.conf 編集¶
コマンド:
期待される出力:
# 編集内容例:
# 主 NTP サーバ
server ntp1.example.com prefer
# 副 NTP サーバ(複数推奨)
server ntp2.example.com
server ntp3.example.com
# ドリフトファイル(時刻補正の累積記録)
driftfile /etc/ntp.drift
# トレースファイル
tracefile /etc/ntp.trace
# loopback への broadcast 制限
restrict default ignore
restrict 127.0.0.1
restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
# サーバ自身も信頼させる(slave クラスタで自分が NTP サーバの場合)
# server 127.127.1.0
# fudge 127.127.1.0 stratum 10
注意点:
preferを 1 サーバだけに付けて優先度を明示。- サーバは 3 台以上推奨(1 台だと故障時に同期失敗、2 台だと真偽判定不能)。
restrict default ignoreでセキュリティ強化(外部からの NTP 問い合わせを拒否)。
Step 3: デーモン起動¶
コマンド:
期待される出力:
# startsrc -s xntpd
0513-059 The xntpd Subsystem has been started. Subsystem PID is 12345.
# lssrc -s xntpd
Subsystem Group PID Status
xntpd tcpip 12345 active
注意点:
chrctcp -S -a xntpdで /etc/rc.tcpip 内のコメントアウトを解除(次回 boot から自動起動)。chrctcp -d xntpdで自動起動無効化。
Step 4: 同期確認(5〜10 分待機後)¶
コマンド:
期待される出力:
# lssrc -ls xntpd
Subsystem Group PID Status
xntpd tcpip 12345 active
Program name: /usr/sbin/ntp4/xntpd
Version: 4.2.8p13
...
synchronised to NTP server (192.168.10.5) at stratum 3
time correct to within 50 ms
polling server every 64 s
# ntpq -p
remote refid st t when poll reach delay offset disp
==============================================================================
*ntp1.example.co 10.0.0.1 2 u 23 64 377 1.234 -0.512 0.456
+ntp2.example.co 10.0.0.1 2 u 45 64 377 1.456 0.234 0.789
ntp3.example.co .INIT. 16 u - 64 0 0.000 0.000 0.000
注意点:
*= 同期中の主サーバ、+= 候補サーバ、-= falsetick(誤った時刻と判定)、空白 = 未到達。reachカラム: 8 進数で 377(= 11111111)が満点(直近 8 回全て応答受信)。offsetがミリ秒オーダー(±10ms 程度)まで収束していれば良好。dispはずれの分散。100ms 超は要調査。
検証¶
チェックリスト:
- [ ]
lssrc -s xntpdでactive - [ ]
lssrc -ls xntpdで "synchronised to NTP server" を含む - [ ]
ntpq -pで少なくとも 1 サーバに*印 - [ ] offset が ±10ms 以内(社内 LAN 内)or ±100ms 以内(インターネット経由)
- [ ]
dateの時刻が他の同期済サーバと数秒以内で一致 - [ ] 次回 boot 後も自動起動(
grep ntp /etc/rc.tcpipがコメントアウトされていない)
長期検証:
- 1 日後に ntpq -p で reach=377 を維持しているか確認
- /etc/ntp.drift にドリフト値が記録されているか確認(cat /etc/ntp.drift)
- HA クラスタの場合: 全ノード間で date を取って数秒以内に揃っているか確認
ロールバック¶
-
デーモン停止:
-
自動起動無効化:
-
設定ファイル復元:
-
(必要なら)手動で時刻を以前の値に戻す:
-
確認:
注意: NTP を止めると時刻ズレが累積する。HA クラスタや Kerberos 環境では rollback ではなく問題解決の方向で対応すべき。
関連エントリ¶
- 用語: TCP/IP, SRC
- コマンド:
lssrc,startsrc,stopsrc,ntpq - 設定: /etc/ntp.conf, /etc/rc.tcpip, /etc/ntp.drift
- 関連手順: cfg-syslog, inc-network-down
典型的な障害パターン¶
症状: ntpq -p で全サーバが空白(reach=0)
- 原因: NTP サーバへの 123/udp 疎通不可、または NTP サーバが応答していない
- 対処:
ping <ntp-server>疎通確認、/usr/sbin/ntp4/ntpdate -d <ntp-server>でデバッグ実行、firewall 確認
症状: lssrc -ls xntpd で unsynchronised
- 原因: システム時刻と NTP サーバの差が大きすぎる(既定で 1000 秒以上)
- 対処: デーモン停止 →
ntpdate -u <ntp-server>で強制同期 → デーモン再起動
症状: ntpd 起動するが * 印が付かない(数分待っても)
- 原因: NTP サーバ側の stratum が高すぎる(16 = 同期されていない)
- 対処: 上位 NTP サーバの状態確認(cascading で全部死んでいる可能性)、別の NTP サーバを ntp.conf に追加
症状: offset が秒オーダーで安定しない
- 原因: ネットワーク遅延が大きい、または仮想環境の時刻ドリフト
- 対処: PowerVM の場合
vio_clock_sync確認、または社内 NTP サーバを構築して low-latency 化
症状: /etc/rc.tcpip 編集後 chrctcp -S -a xntpd がエラー
- 原因: rc.tcpip が手動編集されており構文が壊れている
- 対処:
/etc/rc.tcpipをバックアップから復元 → 再度 chrctcp 実行
出典: S_AIX73_network
cfg-syslog: syslog 出力先の設定¶
重要度: S 級詳細版 / 用途: ログ監査
目的¶
syslogd でログ出力先を設定する。
業務シナリオ: - セキュリティ監査要件で全ログを集中ログサーバへ転送 - アプリ別にログを分離(mail.* → /var/log/maillog 等) - 重要度別にアラート連動(emerg → メール通知) - ログローテーション準備(出力先ファイルを明示)
前提条件¶
- root 権限
- syslogd 起動済(既定で起動)
- 集中ログサーバへ転送する場合: 514/udp 疎通可能、サーバ側でリスナー稼働
- 出力先ファイルを置くディレクトリ存在(既定 /var/adm/ras 等)
手順¶
Step 1: 現状確認・バックアップ¶
コマンド:
# syslogd の状態
lssrc -s syslogd
# 既存設定
cat /etc/syslog.conf
# バックアップ
cp /etc/syslog.conf /etc/syslog.conf.bak.$(date +%Y%m%d)
期待される出力:
# lssrc -s syslogd
Subsystem Group PID Status
syslogd ras 12350 active
# cat /etc/syslog.conf
*.debug /var/adm/ras/syslog.out rotate size 100k files 4
注意点:
- AIX 既定の syslog.conf は最小限。多くのプロセスが
/dev/null状態。 - フィールド区切りは TAB 必須(半角スペースは無視される行あり)。
Step 2: 出力先ファイルを事前作成¶
コマンド:
# 標準出力先
touch /var/log/messages
touch /var/log/secure
touch /var/log/maillog
touch /var/log/cron.log
# 権限設定
chmod 600 /var/log/messages /var/log/secure /var/log/maillog /var/log/cron.log
chown root:system /var/log/*.log
期待される出力:
# ls -la /var/log/
-rw------- 1 root system 0 May 04 10:40 cron.log
-rw------- 1 root system 0 May 04 10:40 maillog
-rw------- 1 root system 0 May 04 10:40 messages
-rw------- 1 root system 0 May 04 10:40 secure
注意点:
- syslogd は出力先ファイルが存在しないと無視する(自動作成しない)。事前作成必須。
- セキュリティログは 600 推奨(一般ユーザに見せない)。
Step 3: /etc/syslog.conf 編集¶
コマンド:
期待される出力:
# 編集内容例(各行は TAB 区切り):
# 全 debug 以上を /var/log/messages に
*.debug /var/log/messages rotate size 1m files 5
# auth 関連を /var/log/secure
auth.info /var/log/secure rotate size 500k files 10
# mail 関連を /var/log/maillog
mail.* /var/log/maillog rotate size 1m files 5
# cron 関連を /var/log/cron.log
*.info;cron.* /var/log/cron.log rotate size 500k files 5
# 集中ログサーバへ転送
*.info @logserver.example.com
# emerg は全ユーザのコンソールへ
*.emerg *
# 監査用に kern.warn 以上を別ファイル
kern.warn /var/log/kern.log rotate time 1d files 30
注意点:
- facility(auth/mail/cron/kern/local0-7 等).priority(emerg/alert/crit/err/warn/notice/info/debug)の組み合わせ。
rotate size 1m files 5で 1MB に達したら .0 〜 .4 まで rotate(5 世代保持)。rotate time 1d files 30で日次 rotate、30 日保持。- 集中転送
@hostは UDP/514 で送信。サーバ側受信設定必須。
Step 4: 設定再読み込み¶
コマンド:
期待される出力:
# refresh -s syslogd
0513-095 The request for subsystem refresh was completed successfully.
# lssrc -s syslogd
Subsystem Group PID Status
syslogd ras 12350 active
注意点:
- PID は変わらない(refresh = SIGHUP 送信、再読み込みのみ)。
- 設定エラー時は syslogd が停止するケースあり。直後に lssrc で active 維持確認必須。
Step 5: テストログ送信¶
コマンド:
# logger でテストメッセージ送信
logger -p user.info "test message from $(hostname) at $(date)"
logger -p auth.warn "test auth warning from $(hostname)"
logger -p mail.err "test mail error from $(hostname)"
# 出力ファイル確認
tail -3 /var/log/messages
tail -3 /var/log/secure
tail -3 /var/log/maillog
期待される出力:
# tail -3 /var/log/messages
May 4 10:42:00 my-server user:notice root: test message from my-server at Mon May 4 10:42:00 JST 2026
# tail -3 /var/log/secure
May 4 10:42:00 my-server auth:warning root: test auth warning from my-server
注意点:
- logger コマンドで自分から自分にテスト送信できるので確認が容易。
- 出力されない場合: ファイル権限、TAB 区切り、syslogd の refresh 確認。
検証¶
チェックリスト:
- [ ] logger テストメッセージが各 facility 別ファイルに分離されて出力
- [ ] 集中ログサーバ転送
@host指定の場合、サーバ側受信ログでも確認 - [ ]
rotate size 1m files 5設定したファイルが 1MB 到達後に .0 .1 .2 … にローテーション - [ ]
*.emerg *設定の場合、logger -p user.emerg "test"で全ログインユーザの端末にメッセージ表示 - [ ] reboot 後も同設定が維持される
長期検証: - 1 週間後に各ファイルがサイズ通り rotate されているか確認 - 集中ログサーバで全 AIX クライアントからの受信ログが揃っているか確認
ロールバック¶
-
設定ファイル復元:
-
syslogd 再読み込み:
-
(オプション)作成した出力ファイル削除:
-
確認:
関連エントリ¶
- 用語: syslogd, errlog, SRC
- コマンド:
lssrc,refresh,logger,errpt - 設定: /etc/syslog.conf, /etc/rc.tcpip
- 関連手順: cfg-errnotify, inc-errpt-hardware-error
典型的な障害パターン¶
症状: logger 送信したメッセージが出力ファイルに現れない
- 原因: 1) 出力ファイル未作成、2) syslog.conf が TAB でなく半角スペース区切り、3) refresh 漏れ
- 対処: ls で出力ファイル存在確認、cat -A /etc/syslog.conf で TAB(^I)確認、refresh 再実行
症状: refresh 後に syslogd が inoperative になる
- 原因: syslog.conf に構文エラー(不正な facility/priority、出力先ディレクトリなし等)
- 対処: errpt | grep syslog でエラー確認、syslog.conf を直前の状態に戻して refresh、その後 1 行ずつ追加
症状: 集中ログサーバに転送されない
- 原因: 1) UDP/514 ブロック、2) サーバ側で remote 受信無効、3) DNS 解決失敗
- 対処: tcpdump で 514/udp 流れているか確認、サーバ側で
-rオプション付き syslogd 起動確認
症状: rotate しているが古いファイルが消えない
- 原因: files 数の指定漏れ(rotate size 1m だけだと無制限 rotate)
- 対処:
rotate size 1m files 5のように files 数を必ず指定
症状: *.emerg メッセージが端末に表示されない
- 原因: AIX のコンソール wall 機能が write 権限なしで失敗
- 対処:
mesg yで wall 受信を有効化(各ユーザ毎)
出典: S_AIX73_osmanagement
cfg-errnotify: errnotify によるエラー通知¶
重要度: A 級詳細版 / 用途: ログ監査
目的¶
errpt の重要エラー検出時に外部コマンド(メール通知等)を起動する仕組みを構築する。
業務上のシナリオ: - ハードウェア障害(DISK_ERR1 等)の即時通知 - セキュリティイベント(USER_LOCKED 等)のメール通知 - 監視サーバ(Nagios/Zabbix)への連携
前提条件¶
- root 権限
- 通知先メールサーバが疎通可能(sendmail 起動済)
- ODM への書き込み権限
手順¶
Step 1: 通知 stanza ファイルの作成¶
コマンド:
期待される出力:
errnotify:
en_name = "hw_alert"
en_persistenceflg = 1
en_class = "H"
en_method = "/usr/bin/echo 'AIX hw error: $9' | mail -s 'AIX errpt' admin@example.com"
注意点:
- en_persistenceflg = 1 で再起動後も保持。
- en_class = H でハードウェアエラーのみ通知。
- en_method の $9 は LABEL フィールドに展開される。
Step 2: ODM への登録¶
コマンド:
期待される出力:
注意点:
- odmadd は出力なし=成功。エラーがあれば標準エラーに出力。
Step 3: 登録確認¶
コマンド:
期待される出力:
errnotify:
en_pid = 0
en_name = "hw_alert"
en_persistenceflg = 1
en_class = "H"
en_method = "/usr/bin/echo 'AIX hw error: $9' | mail -s 'AIX errpt' admin@example.com"
注意点:
- en_pid = 0 が正常(プロセス bind なし)。
Step 4: テスト(疑似ログ生成)¶
コマンド:
期待される出力:
注意点:
- errlogger で生成されるエラーは Class=O(オペレータ)。Class=H で通知設定の場合はテストにならない可能性あり。
- 実ハードウェア障害テストは HMC 等で実施。
検証¶
- odmget で登録確認
- errpt -d H 実行時に該当 LABEL が表示されたら通知メールが届くか確認
- メール受信側ログで配信成功確認
ロールバック¶
odmdelete -q "en_name=hw_alert" -o errnotify
odmget で消えたことを確認。
関連エントリ¶
- 用語: errlog, errnotify, ODM
- コマンド:
errpt,errlogger,odmadd,odmget,odmdelete - 設定: /etc/objrepos/errnotify
- 関連手順: cfg-syslog, inc-errpt-hardware-error
典型的な障害パターン¶
症状: メールが届かない
- 原因: sendmail 未起動、または DNS MX 解決失敗
- 対処: lssrc -s sendmail で起動確認、mailq でキュー確認
症状: odmadd で 0518-307
- 原因: stanza ファイルの構文エラー
- 対処: stanza 形式(en_name = "...")の引用符・スペース確認
症状: 通知が二重に来る
- 原因: 同一 en_name で複数登録
- 対処: odmget で重複確認、odmdelete で整理
出典: S_AIX73_osmanagement
cfg-dump-device: システムダンプデバイスの設定¶
重要度: A 級詳細版 / 用途: ログ監査
目的¶
クラッシュ時のカーネルダンプ出力先 LV を設定し、十分な容量を確保する。
業務上のシナリオ: - カーネルパニック発生時の解析データ保存 - IBM サポートへの提供データ要件 - システム障害解析(dbx + crash 等)の前提整備
前提条件¶
- root 権限
- ダンプを格納する十分なサイズの LV または PV
- /dev/sysdumpnull が既定の場合、本物の dump LV へ切り替え必要
手順¶
Step 1: 現状確認¶
コマンド:
期待される出力:
# sysdumpdev -l
primary /dev/sysdumpnull
secondary /dev/sysdumpnull
copy directory /var/adm/ras
forced copy flag TRUE
always allow dump FALSE
dump compression ON
# sysdumpdev -e
0453-041 Estimated dump size in bytes: 1234567890
注意点:
- primary が /dev/sysdumpnull の場合、ダンプは破棄される(記録されない)。
- -e で必要サイズを確認(実装メモリの一部)。
Step 2: 専用 LV 作成¶
コマンド:
期待される出力:
注意点:
- TYPE=sysdump で dump 専用 LV。
- rootvg 内に作成(boot 時に varyon 済の VG 内推奨)。
Step 3: primary dump device に指定¶
コマンド:
期待される出力:
注意点:
- -P = 永続変更(次回 boot 後も維持)。
Step 4: 確認¶
コマンド:
期待される出力:
primary /dev/dumplv
secondary /dev/sysdumpnull
copy directory /var/adm/ras
forced copy flag TRUE
always allow dump FALSE
dump compression ON
注意点:
- dump compression = ON(既定)でダンプサイズ削減。
検証¶
- sysdumpdev -l で primary が /dev/dumplv
- sysdumpdev -e のサイズ ≤ LV サイズ
- /var/adm/ras に十分な空き容量
ロールバック¶
sysdumpdev -P -p /dev/sysdumpnull rmlv dumplv # 完全削除する場合
関連エントリ¶
- 用語: sysdump, kdb, snap
- コマンド:
sysdumpdev,mklv,rmlv,snap - 設定: /var/adm/ras
- 関連手順: inc-snap-collect, inc-core-dump
典型的な障害パターン¶
症状: sysdumpdev -P で 0453-...
- 原因: 指定 LV が存在しない、または TYPE が sysdump 以外
- 対処: lslv dumplv で TYPE 確認、必要なら mklv で再作成
症状: ダンプ取得時にサイズ不足で truncate
- 原因: 実メモリ増設後に dump LV サイズ更新忘れ
- 対処: sysdumpdev -e で再確認、extendlv で LV 拡張
出典: S_AIX73_osmanagement
cfg-vg-lv: VG / LV の作成¶
重要度: S 級詳細版 / 用途: ストレージFS
目的¶
新規データディスクから VG を作成し、LV と JFS2 FS を切る。
業務シナリオ: - 新規 LPAR 構築時のデータ領域整備 - DB データファイル領域の追加 - バックアップ用 FS の追加 - アプリ用一時領域の隔離(separate VG で切ることで容量・I/O 影響を局所化)
前提条件¶
- root 権限
- 新規 PV が cfgmgr で Available(
lspvで hdisk として見える) - PV が他 VG に未所属(PVID=none、または既存 VG メンバーでない)
- ストレージ側で適切に provisioning 済(SAN/SCSI 両側で OK)
- 計画した VG 名・LV 名・FS マウントポイントが既存と衝突しない
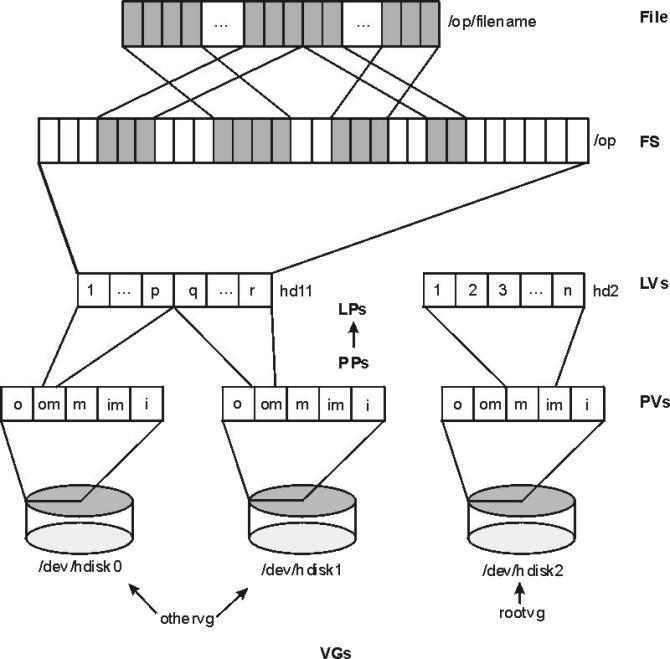
図: LVM の階層構造(File → FS → LV → PV → VG) (出典: AIX 7.3 Performance Management ガイド p.57)
手順¶
Step 1: 対象 PV の確認と PVID 割当¶
コマンド:
# 全 PV 確認
lspv
# 新規 hdisk1 の詳細
lspv hdisk1 2>&1 || echo "hdisk1 not yet usable"
# PVID が none なら割り当て
chdev -l hdisk1 -a pv=yes
# 確認
lspv
期待される出力:
# lspv(chdev 前)
hdisk0 00f6f5d05a1b2c3d rootvg active
hdisk1 none None
# chdev -l hdisk1 -a pv=yes
hdisk1 changed
# lspv(chdev 後)
hdisk0 00f6f5d05a1b2c3d rootvg active
hdisk1 00f6f5d05a1b2c4e None
注意点:
- PVID が
00000000...なら chdev -a pv=clear で完全クリア後に再割当て可能。 - 他システムで使われていた可能性のある PV は最初に必ず lquerypv -h /dev/hdisk1 64 で内容確認。重要データ消えないように。
- MPIO 構成の場合は cfgmgr 後に lspath で全パス Enabled 確認。
Step 2: scalable VG 作成¶
コマンド:
# scalable VG 作成(既定 1024 PV / 256 LV / 32768 PP)
mkvg -S -y datavg -s 64 hdisk1
# 後で hdisk2 を追加する場合
extendvg datavg hdisk2
# 確認
lsvg datavg
期待される出力:
# mkvg -S -y datavg -s 64 hdisk1
0516-1254 mkvg: Changing the PVID in the ODM.
datavg
# lsvg datavg
VOLUME GROUP: datavg VG IDENTIFIER: 00f6f5d000004c000000018745a1b2c3
VG STATE: active PP SIZE: 64 megabyte(s)
VG PERMISSION: read/write TOTAL PPs: 799 (51136 megabytes)
MAX LVs: 256 FREE PPs: 799 (51136 megabytes)
LVs: 0 USED PPs: 0 (0 megabytes)
OPEN LVs: 0 QUORUM: 2 (Enabled)
TOTAL PVs: 1 VG DESCRIPTORS: 2
STALE PVs: 0 STALE PPs: 0
ACTIVE PVs: 1 AUTO ON: yes
MAX PPs per VG: 32768 MAX PVs: 1024
LTG size (Dynamic): 1024 kilobyte(s) AUTO SYNC: no
HOT SPARE: no BB POLICY: relocatable
PV RESTRICTION: none INFINITE RETRY: no
DISK BLOCK SIZE: 512 CRITICAL VG: no
FS SYNC OPTION: no CRITICAL PVs: no
注意点:
- -S で scalable VG(推奨)。-B = Big VG(旧)。デフォルトは Original VG(PV 32 / LV 256 / PP 1016 制限)で時代遅れ。
- PP サイズ -s 64 = 64MB。データサイズが TB 級になる場合は 128 / 256 MB に。小さい LV を多数作る場合は 16 / 32 MB に。
- MAX PPs per VG = 32768、PP 64MB なら最大 2TB/PV。
Step 3: LV 作成¶
コマンド:
# 100 PP(6.4GB)の jfs2 LV を作成
mklv -y datalv -t jfs2 datavg 100
# log LV を別途作成する場合(INLINE log 推奨なので通常不要)
# mklv -y dataloglv -t jfs2log datavg 1
# 確認
lslv datalv
lsvg -l datavg
期待される出力:
# mklv -y datalv -t jfs2 datavg 100
datalv
# lslv datalv
LOGICAL VOLUME: datalv VOLUME GROUP: datavg
LV IDENTIFIER: 00f6f5d000004c000000018745a1b2c3.1 PERMISSION: read/write
VG STATE: active/complete LV STATE: closed/syncd
TYPE: jfs2 WRITE VERIFY: off
MAX LPs: 512 PP SIZE: 64 megabyte(s)
COPIES: 1 SCHED POLICY: parallel
LPs: 100 PPs: 100
STALE PPs: 0 BB POLICY: relocatable
INTER-POLICY: minimum RELOCATABLE: yes
INTRA-POLICY: middle UPPER BOUND: 32
MOUNT POINT: N/A LABEL: None
MIRROR WRITE CONSISTENCY: on/ACTIVE
EACH LP COPY ON A SEPARATE PV ?: yes
Serialize IO ?: NO
INFINITE RETRY: no
DEVICESUBTYPE: DS_LVZ
COPY 1 MIRROR POOL: None
COPY 2 MIRROR POOL: None
COPY 3 MIRROR POOL: None
注意点:
- TYPE=jfs2 で JFS2 用 LV。INLINE log(既定)なので別 jfs2log LV は通常不要。
- ミラー化したい場合は -c 2、-c 3。
- stripe したい場合は -C
-S (性能向上、複数 PV 必要)。
Step 4: JFS2 ファイルシステム作成・マウント¶
コマンド:
# JFS2 FS 作成(自動マウント有効)
crfs -v jfs2 \
-d datalv \
-m /data \
-A yes \
-p rw \
-a logname=INLINE \
-a options=rbrw
# マウント
mount /data
# 所有権・権限設定
chown -R root:system /data
chmod 755 /data
# 確認
mount | grep /data
df -g /data
ls -la /data
期待される出力:
# crfs -v jfs2 -d datalv -m /data -A yes -p rw -a logname=INLINE -a options=rbrw
File system created successfully.
6443372 kilobytes total disk space.
New File System size is 13107200
# mount /data
(出力なし、成功)
# mount | grep /data
/dev/datalv /data jfs2 May 04 10:55 rw,log=INLINE
# df -g /data
Filesystem GB blocks Free %Used Mounted on
/dev/datalv 6.25 6.20 1% /data
# ls -la /data
total 16
drwxr-xr-x 2 root system 256 May 04 10:55 .
drwxr-xr-x 23 root system 4096 May 04 10:55 ..
drwxr-xr-x 2 root system 256 May 04 10:55 lost+found
注意点:
- logname=INLINE が JFS2 のベストプラクティス(log を LV 内に持つことで構造シンプル)。
- -A yes で /etc/filesystems の mount=true、boot 時自動マウント。
- options=rbrw = release behind read/write(大量 sequential I/O でメモリ汚染を抑止、DB ログ等に有効)。
検証¶
チェックリスト:
- [ ]
lsvg datavgで active 表示、TOTAL PVs と TOTAL PPs が期待値 - [ ]
lsvg -l datavgで LV 一覧(datalv)表示、LV STATE=open/syncd - [ ]
df -g /dataで容量表示 - [ ]
mountで /data がマウント表示 - [ ]
touch /data/test.txt && rm /data/test.txtで書き込み・削除成功 - [ ] reboot 後の自動マウント確認(
shutdown -Fr now後df -g /data再確認)
性能確認(オプション):
- dd if=/dev/zero of=/data/test bs=1M count=1024 で書き込み速度測定
- dd if=/data/test of=/dev/null bs=1M で読み込み速度測定
- iostat で当該 hdisk の活動率確認
ロールバック¶
-
アクセス中プロセス停止確認:
-
unmount:
-
FS 削除:
-
LV 削除:
-
VG varyoff & 削除:
-
PV から PVID 削除(オプション、再利用しない場合):
-
確認:
関連エントリ¶
- 用語: LVM, VG, LV, PV, PVID, JFS2, scalable VG
- コマンド:
lspv,lsvg,lslv,mkvg,mklv,crfs,chdev,mount,df - 設定: /etc/filesystems
- 関連手順: cfg-disk-add, cfg-rootvg-mirror, cfg-fs-extend
典型的な障害パターン¶
症状: mkvg で 0516-008 hdiskX is already in another VG
- 原因: PV が他 VG メンバー、または以前のシステム用残骸
- 対処: 確認後
chdev -l hdisk1 -a pv=clearでクリア、または -f 強制(データ消える)
症状: crfs で 0506-928 The operation would lessen the free space below ...
- 原因: VG の空き PP 不足
- 対処:
lsvg datavgで FREE PPs 確認、追加 PV をextendvg
症状: mount が 0506-324 Cannot mount /dev/datalv on /data
- 原因: 対象 LV が他で使用中、または /data が既に他のマウントされている
- 対処:
mountで確認、fuser -cu /dataで使用プロセス特定
症状: reboot 後に /data が自動マウントされない
- 原因: /etc/filesystems の
mount = trueが抜けた、または -A no で作成 - 対処:
chfs -A yes /dataで自動マウント有効化
症状: df で容量表示は OK だが書き込みで Disk full
- 原因: i-node 枯渇(小ファイル大量作成時)
- 対処:
df -i /dataで %Iused 確認、JFS2 は dynamic inode なので通常起こらないが、起こったら FS 拡張
出典: S_AIX73_lvm
cfg-rootvg-mirror: rootvg のミラー化¶
重要度: S 級詳細版 / 用途: ストレージFS
目的¶
rootvg を 2 ディスクにミラーリングして起動ディスク冗長化。
業務シナリオ: - ハードウェア故障時の業務継続(boot ディスク 1 台故障で OS が止まらない) - ストレージマイグレーション中の安全策(旧→新ディスクをミラー後に旧を抜く) - ファームウェア更新等のリスク作業前の保険 - HA クラスタの基本要件(PowerHA 等の前提)
前提条件¶
- root 権限
- 未使用 PV が 1 本(hdisk1 等)、サイズが既存 rootvg の hdisk0 以上
- 新 PV のストレージパス(FC/SAS)が hdisk0 と独立 (同じアダプタの障害で両方失わないため、別アダプタ・別ファブリック推奨)
- ミラー化中の I/O 負荷増(数十分〜数時間)が許容される時間帯
- mksysb バックアップ取得済(ミラー化失敗時のリスク回避)
- /var/adm/ras 配下に十分な空き(ミラー進捗ログ用)
手順¶
Step 1: 事前確認¶
コマンド:
# 現在の rootvg 構成
lsvg rootvg
lsvg -l rootvg
lspv
# 既存ブートリスト
bootlist -m normal -o
# 新 PV の容量確認(hdisk0 以上である必要)
bootinfo -s hdisk0
bootinfo -s hdisk1
期待される出力:
# lsvg rootvg
VOLUME GROUP: rootvg ...
TOTAL PVs: 1 ...
ACTIVE PVs: 1 ...
# lspv
hdisk0 00f6f5d05a1b2c3d rootvg active
hdisk1 00f6f5d05a1b2c4e None
# bootlist -m normal -o
hdisk0 blv=hd5
# bootinfo -s hdisk0
102400
# bootinfo -s hdisk1
102400
注意点:
- hdisk1 サイズ ≥ hdisk0 であること必須。同サイズが理想。
- TOTAL PVs=1 → ミラー前。ミラー後は 2 になる。
Step 2: rootvg に hdisk1 を追加¶
コマンド:
# extendvg で hdisk1 を rootvg に追加
extendvg rootvg hdisk1
# 確認(TOTAL PVs が 2 に)
lsvg rootvg | grep PVs
lspv | grep rootvg
期待される出力:
# extendvg rootvg hdisk1
0516-1254 extendvg: Changing the PVID in the ODM.
# lsvg rootvg | grep PVs
TOTAL PVs: 2 VG DESCRIPTORS: 3
STALE PVs: 0 STALE PPs: 0
ACTIVE PVs: 2 AUTO ON: yes
MAX PPs per VG: 32768 MAX PVs: 1024
# lspv | grep rootvg
hdisk0 00f6f5d05a1b2c3d rootvg active
hdisk1 00f6f5d05a1b2c4e rootvg active
注意点:
- VG DESCRIPTORS: 3 = 2 PV になると VGDA は 3 つ(quorum 維持のため)。
- extendvg で
Quorum lost警告が出たら -f で強制(リスクあり)。
Step 3: rootvg ミラー実行¶
コマンド:
# 同期モードで全 LV をミラー(推奨)
# -S = sync mode、進捗が見える
mirrorvg -S rootvg hdisk1
# 大きい rootvg の場合は数十分〜数時間かかる
# 別 ssh セッションから進捗確認:
# lsvg -l rootvg | awk '$5 != "open/syncd" && $5 != "closed/syncd" {print}'
# 同期完了確認
lsvg -l rootvg
期待される出力:
# mirrorvg -S rootvg hdisk1
0516-1124 mirrorvg: Quorum requirement changed, please save user environment definitions.
0516-1126 mirrorvg: rootvg successfully mirrored, user should perform bosboot of system to initialize boot records. Then, user must modify bootlist to include: hdisk0 hdisk1.
# lsvg -l rootvg
rootvg:
LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT
hd5 boot 1 2 2 closed/syncd N/A
hd6 paging 8 16 2 open/syncd N/A
hd8 jfs2log 1 2 2 open/syncd N/A
hd4 jfs2 4 8 2 open/syncd /
hd2 jfs2 16 32 2 open/syncd /usr
hd9var jfs2 2 4 2 open/syncd /var
hd3 jfs2 4 8 2 open/syncd /tmp
hd1 jfs2 2 4 2 open/syncd /home
hd10opt jfs2 3 6 2 open/syncd /opt
hd11admin jfs2 1 2 2 open/syncd /admin
livedump jfs2 2 4 2 open/syncd /var/adm/ras/livedump
注意点:
- 全 LV で PPs = LPs * 2 になっていれば成功(ミラー化完了)。
- STALE 列が 0 のまま、open/syncd ステートで揃うこと。
- 途中で I/O エラーが出たら lsvg -l 出力に stale 表示、
syncvgで再同期。
Step 4: ブートイメージを両 PV に作成¶
コマンド:
# 既存 hdisk0 の BLV 更新
bosboot -ad /dev/hdisk0
# 新 hdisk1 への BLV 作成
bosboot -ad /dev/hdisk1
# ブートリスト更新
bootlist -m normal hdisk0 hdisk1
bootlist -m normal -o
期待される出力:
# bosboot -ad /dev/hdisk0
bosboot: Boot image is 99008 512 byte blocks.
# bosboot -ad /dev/hdisk1
bosboot: Boot image is 99008 512 byte blocks.
# bootlist -m normal -o
hdisk0 blv=hd5
hdisk1 blv=hd5
注意点:
- 両ディスクに BLV を入れることが必須。片方しか入れていないと冗長性なし。
- blv=hd5 が標準(boot LV 名)。
bootlist -m normal hdisk0 hdisk1で順序指定。 - サービスモード boot 用にも入れたければ
bootlist -m service hdisk0 hdisk1。
Step 5: Quorum と STALE の確認¶
コマンド:
# Quorum 状態
lsvg rootvg | grep -i quorum
# STALE 件数
lsvg rootvg | grep -i stale
lsvg -l rootvg | awk '$5 ~ /stale/ {print}'
# 必要なら STALE PP を再同期
syncvg -v -P 4 rootvg
期待される出力:
# lsvg rootvg | grep -i quorum
QUORUM: 2 (Enabled)
# lsvg -l rootvg | awk '$5 ~ /stale/ {print}'
(出力なし=STALE 0)
# syncvg -v -P 4 rootvg
(出力なし、成功)
注意点:
- QUORUM Enabled で 2/3 VGDA に access できれば varyon 維持。1/3 になれば全停止。
- rootvg のミラーで quorum off にすることも可(lsvg
0516-732)。
検証¶
チェックリスト:
- [ ]
lsvg rootvgで TOTAL PVs=2、ACTIVE PVs=2、STALE PVs=0 - [ ]
lsvg -l rootvgで全 LV が PPs=LPs*2、open/syncd - [ ]
bootlist -m normal -oで hdisk0 hdisk1 両方表示 - [ ]
bosboot -qで BLV サイズ表示エラーなし - [ ] 疑似 fail テスト(テスト環境のみ推奨):
- HMC で hdisk1 を一時切断 → 業務継続することを確認
- hdisk1 復活 →
varyonvg rootvgまたは syncvg で同期回復 - [ ] reboot 後も TOTAL PVs=2、open/syncd 維持
重要: 本番 rootvg で疑似 fail テストはしない(数時間の syncvg が走る)。テスト環境または mksysb restore した環境で。
ロールバック¶
ミラー解除手順:
-
ミラー解除(unmirrorvg):
-
hdisk1 を rootvg から削除:
-
ブートリストから hdisk1 削除:
-
(オプション)hdisk1 を ODM から削除:
-
確認:
注意: ミラー解除中も VG は active 維持。unmirrorvg 中に I/O は継続可能。
関連エントリ¶
- 用語: LVM, VG, PV, BLV, hd5
- コマンド:
lspv,lsvg,extendvg,mirrorvg,unmirrorvg,syncvg,bosboot,bootlist - 関連手順: cfg-vg-lv, inc-disk-replace, inc-boot-fail-led
典型的な障害パターン¶
症状: extendvg で 0516-1170 hdisk1 is too small
- 原因: 新 PV のサイズが既存 PV より小さい
- 対処: ストレージ側で大きい PV を切り出して再 cfgmgr
症状: mirrorvg 中に 0516-792 syncvg エラー
- 原因: 片方の PV に I/O エラー(ハードウェア不良)
- 対処: errpt で hdisk エラー確認、ストレージ側で PV 健全性確認、必要なら別 PV に交換
症状: ミラー完了後 lsvg -l rootvg に stale 表示
- 原因: syncvg 中に I/O エラーで一部 PP が同期できなかった
- 対処:
syncvg -v -P 4 rootvgで再同期、ハード障害なら PV 交換
症状: reboot 後に hdisk1 から boot しない
- 原因: bosboot を hdisk1 に実行していない、または bootlist 順序が hdisk0 のみ
- 対処:
bosboot -ad /dev/hdisk1実行、bootlist 確認
症状: 片方の PV を抜いたら quorum loss で OS hang
- 原因: quorum check が enabled かつ 2/3 VGDA loss
- 対処: 事前に
chvg -Qn rootvgで quorum off(リスク許容時)、または 3 PV 構成に変更
出典: S_AIX73_lvm
cfg-fs-extend: ファイルシステムの拡張¶
重要度: S 級詳細版 / 用途: ストレージFS
目的¶
FS 容量不足時に動的に拡張する。
業務シナリオ: - /var/log や /tmp の急速な使用率上昇への即応 - DB データファイル領域の計画的拡張 - monthly メンテで使用率 80% 超過 FS の予防的拡張 - アプリログがローテーション無しで蓄積した結果の応急処置
頻度: 月数回〜十数回、FS full アラート時の最頻出作業。
前提条件¶
- root 権限
- 拡張先 VG に空き PP がある(無い場合は extendvg で PV 追加が事前必要)
- 業務継続中でも実施可能(オンライン拡張)
- JFS2 の場合は縮小不可なので慎重に(過剰拡張は元に戻せない)
手順¶
Step 1: 現状確認¶
コマンド:
# 対象 FS の現在容量
df -g /var
# 基底 LV 確認
lsfs /var
# VG の空き PP 確認
lsvg rootvg | grep -i free
# VG の詳細
lsvg rootvg
期待される出力:
# df -g /var
Filesystem GB blocks Free %Used Mounted on
/dev/hd9var 2.00 0.05 98% /var
# lsfs /var
Name Nodename Mount Pt VFS Size Options Auto Accounting
/dev/hd9var -- /var jfs2 4194304 -- yes no
# lsvg rootvg
VOLUME GROUP: rootvg ...
FREE PPs: 50 (3200 megabytes) ...
PP SIZE: 64 megabyte(s) ...
注意点:
- FREE PPs が拡張サイズ ÷ PP SIZE 以上必要。例: 1GB 拡張なら 16 PP(PP=64MB の場合)必要。
- Size 列は 512 byte ブロック数(4194304 = 2GB)。
Step 2: FS 拡張実行(相対値)¶
コマンド:
期待される出力:
# chfs -a size=+1G /var
Filesystem size changed to 6291456
# df -g /var
Filesystem GB blocks Free %Used Mounted on
/dev/hd9var 3.00 1.00 67% /var
# lsfs /var
Name Nodename Mount Pt VFS Size Options Auto Accounting
/dev/hd9var -- /var jfs2 6291456 -- yes no
注意点:
- +1G の
+を忘れると絶対値設定になり予期せぬ結果(既存 FS が縮小される)。要注意。 - JFS2 は 16 PP 単位で拡張される(PP=64MB なら 1GB 単位)。1.5GB 指定でも 2GB に丸める。
- 拡張完了は通常数秒。大容量(数百 GB)でも数分以内。
Step 3: アプリ側で空き容量を認識させる¶
コマンド:
# 多くのアプリは df の出力を即時反映する
df -g /var
# DB(Db2 等)の場合は table space 拡張も別途必要
# Oracle の場合は file system size 自動認識
# アプリ側のキャッシュをクリアする必要があるかも
# log rotate を再起動(ログ蓄積が原因なら)
refresh -s syslogd
期待される出力:
注意点:
- 通常 OS レベルで chfs 完了 = アプリで使用可能。
- ただし、アプリが内部でディスク残量をキャッシュしている場合(旧式 DB 等)は restart 必要。
検証¶
チェックリスト:
- [ ]
df -g /varの GB blocks が拡張後の値 - [ ]
df -g /varの %Used が下がっている - [ ] アプリログに
disk fullno space leftエラーが出ていない - [ ]
chfsの戻り値 0 - [ ]
lsvg rootvgの FREE PPs が拡張分減っている
長期検証: - 1 週間後に再度 %Used を観察、増加傾向なら根本原因(ログ蓄積等)対処
ロールバック¶
JFS2 は縮小可能だがリスク大。データ損失リスクがあるため事前バックアップ必須。
通常は rollback しない。誤って過剰拡張した場合は次のメンテで縮小、または無視(容量に余裕があるだけ)。
VG 全体を返したい場合(PV を取り戻したい):
1. /var の使用量を縮小サイズ未満に減らす(不要ファイル削除)
2. chfs -a size=2G /var
3. (オプション)LV を rmlv して別用途へ
関連エントリ¶
- 用語: JFS2, LV, PP
- コマンド:
df,chfs,lsfs,lsvg,extendvg - 設定: /etc/filesystems
- 関連手順: cfg-vg-lv, inc-fs-full
典型的な障害パターン¶
症状: chfs -a size=+1G で 0516-787 not enough free physical partitions
- 原因: VG に空き PP 不足
- 対処:
extendvg <vg> <new_pv>で PV 追加してから再 chfs、または別 FS の縮小で空き作る
症状: 拡張完了後も df -g の容量が増えない
- 原因: FS が unmount 状態、または別の LV を見ている
- 対処:
mountで確認、umount→mountで再認識
症状: アプリが拡張後も disk full エラーを出し続ける
- 原因: アプリ内部でキャッシュ、または別 FS のエラー
- 対処:
df -gで全 FS 確認、アプリ再起動
症状: 誤って絶対値で小さく指定(例: size=1G を既存 4GB に対し)
- 原因: + 漏れで縮小コマンドになる
- 対処: 重要データある場合は実行前バックアップ必須。データ損失リスク。事前 yes/no 確認に注目。
症状: JFS(旧)で拡張が i-node 不足で失敗
- 原因: JFS は inode 固定。NBPI(bytes per i-node)の制約。
- 対処: JFS は新規拡張を諦め、JFS2 へ移行(mksysb 経由)
出典: S_AIX73_jfs2
cfg-user-add: ユーザ追加とパスワードポリシー¶
重要度: S 級詳細版 / 用途: ユーザ認証
目的¶
新規ユーザを追加し、パスワードポリシー(試行回数・有効期限・最小長)を設定する。
業務シナリオ: - 新入社員・委託先メンバー追加 - アプリ専用サービスアカウント作成(DB owner、Web app 等) - セキュリティ監査要件のパスワードポリシー強化(minlen=12 等) - グループ別の home directory / shell 既定値統一
前提条件¶
- root 権限(または RBAC
aix.security.user.create認可) - /home の十分な空き容量(ユーザごとに数 MB〜)
- グループが既存(
lsgroup ALLで確認、無ければ事前にmkgroup) - パスワードポリシー要件(社内セキュリティルール)の確認
手順¶
Step 1: 事前確認¶
コマンド:
# 既存ユーザ確認
lsuser ALL | head -20
lsuser alice 2>&1 # 当該ユーザが既に存在するか
# 既存グループ確認
lsgroup ALL
# 次に空いてる UID 確認
cat /etc/passwd | awk -F: '{print $3}' | sort -n | tail
期待される出力:
注意点:
- UID は 1000 以上を一般ユーザに割当てるのが慣例(1〜999 はシステム予約)。
- 他システムと UID を揃える場合は
id <user>を別サーバで取って合わせる(NFS シェアでの permission 一致のため)。
Step 2: ユーザ作成¶
コマンド:
# 基本作成(ID, home, shell 指定)
mkuser id=2001 \
home=/home/alice \
shell=/usr/bin/ksh \
gecos="Alice Smith - Sales Dept" \
pgrp=staff \
groups=staff,printq \
maxage=12 \
maxrepeats=3 \
minlen=12 \
minother=2 \
histsize=10 \
loginretries=5 \
alice
# /etc/passwd 確認
grep alice /etc/passwd
# /etc/security/user 確認
lsuser -f alice
期待される出力:
# grep alice /etc/passwd
alice:!:2001:1::/home/alice:/usr/bin/ksh
# lsuser -f alice
alice:
id=2001
pgrp=staff
groups=staff,printq
home=/home/alice
shell=/usr/bin/ksh
gecos=Alice Smith - Sales Dept
login=true
su=true
rlogin=true
daemon=true
admin=false
sugroups=ALL
maxage=12
maxrepeats=3
minlen=12
minother=2
histsize=10
loginretries=5
...
注意点:
- ! が /etc/passwd の 2 番目フィールドにあるのは「パスワード未設定 = ロック」状態。次の step でパスワード設定する。
pgrp= primary group、groups= secondary groups(カンマ区切り)。gecosはフルネーム等の説明文(finger コマンド等で表示)。
Step 3: 初期パスワード設定と強制変更フラグ¶
コマンド:
# 初期パスワード設定
passwd alice
# 入力(root が一時パスワードを 2 回入力)
# 次回ログイン時にパスワード強制変更を要求
pwdadm -f ADMCHG alice
# パスワード状態確認
lsuser -a passwordchanged alice
# /etc/security/passwd 確認(root のみ)
grep -A 3 alice /etc/security/passwd
期待される出力:
# passwd alice
Changing password for "alice"
alice's New password:
Enter the new password again:
# pwdadm -f ADMCHG alice
(出力なし、成功)
# grep -A 3 alice /etc/security/passwd
alice:
password = (encrypted hash)
lastupdate = 1683200000
flags = ADMCHG
注意点:
flags = ADMCHGで次回ログイン時にユーザ自身に新パスワード入力を強制。- 初期パスワードは安全な経路で本人に伝達(メール平文や Slack 平文は NG)。
- PAM/LDAP 統合環境では passwd の出力先が違うため、対応する管理ツール使用。
Step 4: home ディレクトリの初期化と所有権¶
コマンド:
# home ディレクトリの所有権確認
ls -ld /home/alice
# 必要なら所有権を alice に
chown alice:staff /home/alice
chmod 750 /home/alice
# .profile / .kshrc を雛形からコピー
cp /etc/security/.profile /home/alice/.profile
chown alice:staff /home/alice/.profile
chmod 600 /home/alice/.profile
期待される出力:
注意点:
- mkuser は通常 home を作成するが、所有権が root のままになるケースあり(特にカスタムオプション時)。
- /etc/security/.profile はシステム既定の雛形。組織独自の .profile があればそちらをコピー。
Step 5: デフォルトポリシーの組織レベル変更(オプション)¶
コマンド:
# 全ユーザのデフォルトに minlen=12 を設定
chsec -f /etc/security/user -a minlen=12 -s default
chsec -f /etc/security/user -a minother=2 -s default
chsec -f /etc/security/user -a maxage=12 -s default
chsec -f /etc/security/user -a histsize=10 -s default
# 確認
lsuser -a minlen minother maxage histsize default
期待される出力:
# lsuser -a minlen minother maxage histsize default
default minlen=12 minother=2 maxage=12 histsize=10
注意点:
- default stanza はこれ以降に作成するユーザの既定値になる。既存ユーザは影響を受けない(個別に chuser で設定必要)。
- 全既存ユーザに一括反映する場合:
for u in $(lsuser -c ALL | tail +2 | cut -d: -f1); do chuser minlen=12 $u; done
検証¶
チェックリスト:
- [ ]
lsuser aliceで属性表示成功 - [ ] alice として ssh / telnet ログイン成功
- [ ] 初回ログイン時にパスワード変更要求が出る(ADMCHG が効いている)
- [ ] パスワード変更時に minlen=12, minother=2 が enforce される(短いパスワードが拒否される)
- [ ] secondary groups(printq 等)の権限が機能する
- [ ] home ディレクトリで .profile が読み込まれる(プロンプト・PATH 設定が適用)
- [ ] /etc/security/limits の default stanza が適用される(ulimit 確認)
否定テスト: - minlen=12 設定下で 8 文字パスワードを設定 → エラーで拒否されること - loginretries=5 設定下で 5 回連続失敗 → アカウントロックされること
ロールバック¶
-
ユーザ削除(home も含めて):
-
(オプション)/etc/passwd, /etc/group, /etc/security/* に残骸がないか確認:
-
デフォルトポリシー変更を巻き戻す:
-
メールスプール削除(必要なら):
関連エントリ¶
- 用語: RBAC, user
- コマンド:
mkuser,rmuser,chuser,lsuser,passwd,pwdadm,chsec - 設定: /etc/security/user, /etc/security/passwd, /etc/passwd, /etc/group
- 関連手順: cfg-passwd-policy, inc-login-locked
典型的な障害パターン¶
症状: mkuser で 3004-694 Error reading id attribute
- 原因: 指定 UID が既に他ユーザで使われている
- 対処:
lsuser -a id ALL | grep 2001で重複確認、別 UID を選ぶ
症状: alice ログイン直後に Cannot find your home directory
- 原因: home ディレクトリ未作成、または所有権が root のまま
- 対処: mkdir + chown alice:staff /home/alice、chmod 750
症状: passwd alice で Password must have at least N characters
- 原因: minlen 制約が enforce されているが入力が短い
- 対処: より長いパスワード入力。または一時的に
chuser minlen=8 aliceで緩和
症状: ssh で alice ログインが Connection closed
- 原因: /etc/security/user で
rlogin=falseまたは ssh-specific の制限 - 対処:
lsuser -a rlogin login alice確認、chuser rlogin=true login=true alice
症状: secondary group の権限(例: printq)が effective にならない
- 原因: ログイン後に supplementary groups が読み込まれていない
- 対処: alice 再ログイン、または
id aliceで groups 表示確認
出典: S_AIX73_security
cfg-package-install: fileset のインストール / 更新¶
重要度: S 級詳細版 / 用途: パッケージ
目的¶
BFF パッケージ(fileset)の適用。
業務シナリオ: - 月次の TL/SP 適用(セキュリティパッチ) - 新しいアプリ用ライブラリ追加(bos.adt.libm 等) - IBM Java、PowerHA、PowerVC エージェント等の追加導入 - 互換性 fileset の追加(旧アプリサポート用)
前提条件¶
- root 権限
- ソース(DVD、NFS マウント、ローカルディレクトリ)が用意されている
- /usr に十分な空き(適用するパッケージサイズの数倍)
- /tmp に十分な空き(一時展開用、数百 MB〜)
- mksysb バックアップ取得済(特に大規模 update)
- 業務影響が許容される時間帯(service pack はカーネル更新の可能性あり)
手順¶
Step 1: 事前準備とプレビュー¶
コマンド:
# 現在の OS レベル
oslevel -s
# 適用対象 fileset の確認
ls /mnt/lpp_source/
# /usr の空き
df -g /usr
# プレビュー実行(試験のみ、実 install しない)
installp -p -aXd /mnt/lpp_source bos.adt.libm
# update_all のプレビュー
installp -p -aXd /mnt/lpp_source all
期待される出力:
# oslevel -s
7300-04-00-2546
# installp -p -aXd /mnt/lpp_source bos.adt.libm
....
SUCCESSES
---------
Filesets listed in this section passed pre-installation verification
and will be installed.
Selected Filesets
-----------------
bos.adt.libm 7.3.4.0 # Base Application D...
<< End of Success Section >>
FILESET STATISTICS
------------------
1 Selected to be installed, of which:
1 Passed pre-installation verification
----
1 Total to be installed
注意点:
- プレビュー実行は必須。前提条件不足、依存 fileset 不足等が事前に分かる。
- Pre-installation verification の Failures セクションがあれば対処してから本実行。
Step 2: 実適用(apply モード)¶
コマンド:
# 実適用(applied 状態、後で reject 可能)
installp -aXd /mnt/lpp_source bos.adt.libm
# 大量 update の場合は update_all
installp -aXd /mnt/lpp_source all
# verbose ログを取りたい場合
installp -aXd -V4 /mnt/lpp_source bos.adt.libm 2>&1 | tee /tmp/install.log
期待される出力:
# installp -aXd /mnt/lpp_source bos.adt.libm
+-----------------------------------------------------------------------------+
Pre-installation Verification...
+-----------------------------------------------------------------------------+
... 中略 ...
+-----------------------------------------------------------------------------+
Installing Software...
+-----------------------------------------------------------------------------+
installp: APPLYING software for:
bos.adt.libm 7.3.4.0
... 中略 ...
Installation Summary
--------------------
Name Level Part Event Result
-------------------------------------------------------------------------------
bos.adt.libm 7.3.4.0 USR APPLY SUCCESS
注意点:
- Result=SUCCESS が出ていれば成功。FAILURE / WARNING は対処必要。
- applied 状態は後で reject(取り消し)可能。commit 後は不可。
- -X = FS 自動拡張、-Y = ライセンス自動受諾、-w = 進捗表示。
Step 3: 適用結果の検証¶
コマンド:
# 適用済 fileset の状態確認
lslpp -L bos.adt.libm
# 整合性チェック
lppchk -v
lppchk -c bos.adt.libm
# 履歴確認
lslpp -h bos.adt.libm
# OS レベル確認
oslevel -s
期待される出力:
# lslpp -L bos.adt.libm
Fileset Level State Type Description
----------------------------------------------------------------
bos.adt.libm 7.3.4.0 C F Base Application Develop...
# lppchk -v
(出力なしなら整合 OK)
# lslpp -h bos.adt.libm
Fileset Level Action Status Date Time
----------------------------------------------------------------------
Path: /usr/lib/objrepos
bos.adt.libm
7.3.4.0 APPLY COMPLETE 05/04/26 10:50:00
7.3.4.0 COMMIT COMPLETE 05/04/26 10:50:00
注意点:
- State 列:
C=committed、A=applied、B=broken、?=unknown。 lppchk -vで出力があるなら整合性問題あり(symlink 不整合等)。要対処。- applied → commit 移行は
installp -c <fileset>。commit 後は reject 不可。
Step 4: 再起動が必要かの判定¶
コマンド:
# bosboot が必要か確認(カーネル fileset 更新時)
bosboot -q
# 必要なら BLV 再作成
bosboot -ad /dev/ipldevice
# multibos / alt_disk_install 環境なら別途配慮
# 通常 update でも /usr/lib/boot 配下が変更されたら bosboot 必要
期待される出力:
注意点:
- カーネル関連 fileset (bos.mp64, bos.rte.* の一部) 更新後は bosboot + reboot 必須。
- 再起動なしで使えるかは fileset README または lppchk 後のメッセージ確認。
- PowerHA 環境では update 中はクラスタ片肺運転。事前に passive 化。
検証¶
チェックリスト:
- [ ]
lslpp -L <fileset>で State=C または State=A - [ ] Installation Summary に Result=SUCCESS
- [ ]
lppchk -vで出力なし(整合性 OK) - [ ]
oslevel -s等で期待した version 表示 - [ ] アプリから当該 fileset の機能が使える(例: bos.adt.libm なら libm.a が使える C プログラムがリンクできる)
- [ ] カーネル関連の場合、
bosboot -q実行 → reboot 後正常起動
長期検証: - 1 週間後にエラーログ(errpt)に当該 fileset 関連のエラーが出ていないか - 関連サービスが安定動作している(短期で fail back していない)
ロールバック¶
applied 状態の場合(推奨):
committed 状態の場合(reject 不可):
update_all で多数 fileset を入れた後の rollback:
複数 fileset の依存関係で簡単に reject できないケース多数。 事前に取得した mksysb から restore が確実:
関連エントリ¶
- 用語: fileset, LPP, VRMF, TL, SP
- コマンド:
installp,lslpp,instfix,oslevel,lppchk,bosboot - 設定: /usr/lib/objrepos
- 関連手順: cfg-mksysb-backup, inc-package-install-fail
典型的な障害パターン¶
症状: Pre-installation verification で Failures セクションに Selected fileset requisites are missing
- 原因: 依存 fileset が未インストール、または別バージョン
- 対処: Failures に列挙された fileset を
installp -aXdで先に入れる、-g オプションで自動取り込み
症状: /usr 容量不足で失敗
- 原因: -X オプション忘れ、または /usr の VG に空き PP なし
- 対処: -X 追加、または
chfs -a size=+1G /usrで事前拡張
症状: bos.net.tcp.sendmail 7.3.0.0 適用で libcrypto_compat.a エラー
- 原因: OpenSSL 3.0 で libcrypto_compat が削除されているが古い sendmail が依存
- 対処: lpp_source に 7.3.3 update を含めて update_all で進める(既知の workaround)
症状: Installation Summary に Result=FAILED
- 原因: 様々(ディスクエラー、署名検証失敗、依存解決失敗)
- 対処:
tail -100 /var/adm/ras/installp.summary.logで詳細確認、IBM サポート相談
症状: applied で reject すると元の version でなく無くなる
- 原因: 新規 fileset を applied → reject すると完全削除される(仕様)
- 対処: 事前に旧 version の存在を
lslpp -hで確認、新規導入は事前にバックアップ
出典: S_AIX73_install
cfg-mksysb-backup: mksysb による rootvg バックアップ¶
重要度: S 級詳細版 / 用途: バックアップ
目的¶
rootvg の bootable バックアップを取得する。
業務シナリオ: - 月次の定期バックアップ(DR 対策) - 重要 update 直前のバックアップ(rollback 手段) - 別 LPAR への OS clone(同 mksysb から restore で複製作成) - 老朽化ハード からの移行ベース(新ハードへ mksysb 経由 restore)
前提条件¶
- root 権限
- 保管先(テープ、NFS、ローカル FS)に rootvg 容量以上の空き
- 一般的に rootvg 実使用量と同等のサイズ(圧縮なしで)
- mksysb 実行中の I/O 負荷増(数十分〜数時間、データ量による)が許容される
- /tmp に十分な空き(image.data 一時ファイル等)
- NIM サーバ連携の場合、NIM master が稼働
手順¶
Step 1: 事前確認¶
コマンド:
# rootvg 構成確認
lsvg rootvg
lsvg -l rootvg
# 実使用容量確認
du -sg / /usr /var /tmp /home /opt
# 保管先 FS の空き
df -g /backup
# 既存の image.data 確認
ls -la /image.data /etc/exclude.rootvg 2>&1
期待される出力:
# lsvg rootvg
TOTAL PVs: 1 VG IDENTIFIER: ...
TOTAL PPs: 399 (25536 megabytes) ...
USED PPs: 85 (5440 megabytes) ...
# du -sg /
2.5 /
1.8 /usr
0.3 /var
0.1 /tmp
0.05 /home
0.5 /opt
# df -g /backup
Filesystem GB blocks Free %Used Mounted on
/dev/backuplv 50.00 45.00 10% /backup
注意点:
- 実使用量の 1.5 倍程度の空き を保管先に確保すると安全。
- /etc/exclude.rootvg に除外パスを書ける(/var/log 等を除外して軽量化可能)。
Step 2: 除外ファイル設定(オプション)¶
コマンド:
期待される出力:
# 編集内容例(regex で記述):
^./var/log/.*
^./var/spool/.*
^./tmp/.*
^./home/.*/Trash/.*
# 注意: ^./ で始まる行は cwd 直下からの相対パス指定
注意点:
- ログ・一時ファイルを除外で大幅軽量化。ただし業務関係のものは含める。
- 除外しすぎると restore 時に必要ファイル無くなる。慎重に。
Step 3: mksysb 実行¶
コマンド:
# ファイルへの mksysb(推奨:NFS マウント先 or 大容量 FS)
mksysb -i -X -e /backup/$(hostname)_$(date +%Y%m%d_%H%M%S).mksysb
# テープへの mksysb
# mksysb -i /dev/rmt0
# SMIT 経由(対話的)
# smitty mksysb
期待される出力:
Backup in progress, please wait...
Creating list of files to back up.
Backing up files...
Backup of 12345 files....
12345 of 12345 files (100%)
0512-038 mksysb: Backup Completed Successfully.
# ls -lh /backup/
-rw-r--r-- 1 root system 3.2G May 04 11:00 myhost_20260504_110000.mksysb
注意点:
- -i: image.data を自動更新。
/image.dataに LV map 等を保存。 - -X: FS 不足なら自動拡張。
- -e: /etc/exclude.rootvg を適用。
- テープでは bs(ブロックサイズ)に注意。1024 (512 byte = 1 block * 1024) が標準。
- 進捗は標準エラー出力。リダイレクトする場合
2>&1必要。
Step 4: バックアップ完了確認¶
コマンド:
# ファイルサイズ確認
ls -lh /backup/*.mksysb | tail -3
# image.data 確認
file /image.data
head /image.data
# tar として一覧表示できるか
restore -Tqf /backup/<filename>.mksysb | head -30
# md5sum 取得(後の整合性確認用)
md5sum /backup/<filename>.mksysb > /backup/<filename>.mksysb.md5
期待される出力:
# ls -lh /backup/*.mksysb | tail -3
-rw-r--r-- 1 root system 3.2G May 04 11:00 myhost_20260504_110000.mksysb
# restore -Tqf /backup/myhost_20260504_110000.mksysb | head -30
New volume on /backup/myhost_20260504_110000.mksysb:
Cluster size is 51200 bytes (100 blocks).
The volume number is 1.
The backup date is: Mon May 4 11:00:00 JST 2026
Files are backed up by name.
The user is root.
0 -rw-r--r-- 1 0 0 0 May 04 10:00 1970 ./.profile
45123 -rw-r--r-- 1 0 0 45123 Apr 12 06:19 1970 ./image.data
注意点:
- ファイルサイズ妥当性: 数 GB〜数十 GB が標準(rootvg 実サイズに依存)。
restore -Tqfでアーカイブ目次表示。エラーなく出力されれば破損なし。- md5sum で後日の改ざん検知・転送整合性確認。
Step 5: NIM resource として登録(NIM 環境のみ)¶
コマンド:
# NIM サーバで mksysb resource として登録
# NIM サーバ側で実行:
nim -o define -t mksysb \
-a server=master \
-a location=/backup/myhost_20260504.mksysb \
myhost_mksysb_20260504
# 確認
lsnim -t mksysb
期待される出力:
# lsnim -t mksysb
boot resources boot
nim_script resources nim_script
myhost_mksysb_20260504 resources mksysb
注意点:
- NIM resource として登録すれば、別 LPAR の bos_inst で
mksysb=myhost_mksysb_20260504を指定して bootable restore 可能。 - DR 用クローン作成や LPAR 移行時に有効。
検証¶
チェックリスト:
- [ ] mksysb 出力末尾に
0512-038 mksysb: Backup Completed Successfully. - [ ] ファイルサイズが妥当(数 GB〜数十 GB)
- [ ]
restore -Tqf <mksysb>で目次表示エラーなし - [ ] /image.data 存在、内容に LV 一覧あり
- [ ] md5sum 取得済(保管先と複製先で値一致)
- [ ] バックアップサイクル(月次・週次)に組み込まれた
実用検証(推奨、テスト環境): - 取得した mksysb から実際に bootable restore できるか NIM 経由で別 LPAR にテスト - restore 後にアプリが起動することを確認
ロールバック¶
mksysb 取得自体に rollback はない(読み取り専用操作)。
取得済 mksysb の削除:
NIM resource 削除:
保管期間管理:
- 古い mksysb は世代管理して定期削除(例: 直近 3 世代保持、それ以前は削除)
- find /backup -name "*.mksysb" -mtime +90 -delete
関連エントリ¶
- 用語: mksysb, image.data, NIM, VRMF
- コマンド:
mksysb,savevg,restore,lsvg,lsmksysb - 設定: /image.data, /etc/exclude.rootvg
- 関連手順: cfg-package-install, inc-disk-replace
典型的な障害パターン¶
症状: mksysb 中に 0511-000 Cannot create temporary file
- 原因: /tmp の空き不足
- 対処: /tmp の不要ファイル削除、または
chfs -a size=+1G /tmp
症状: mksysb 中に 0511-160 ... I/O error on backup device
- 原因: 保管先デバイスのエラー(テープ不良、NFS タイムアウト等)
- 対処: errpt 確認、別保管先で再試行、テープなら別ドライブで
症状: ファイルサイズが 0 で完了表示
- 原因: 保管先 FS が full または write 権限なし
- 対処:
df -g <dest>確認、ls -ld <dest>で権限確認
症状: exclude.rootvg が効かない
- 原因: regex 構文間違い(^./ で始まる必要)
- 対処:
man mksysbで exclude.rootvg 仕様確認、テスト regex をmksysb -i ...前にプレビュー
症状: restore -Tqf で Restore: 0511-159 ... cannot open: ...
- 原因: mksysb ファイルが破損(途中切断、メディア不良)
- 対処: 再 mksysb 取得、md5sum で整合性確認
出典: S_AIX73_install
cfg-passwd-policy: パスワードロック解除(強制リセット)¶
重要度: S 級詳細版 / 用途: ユーザ認証
目的¶
loginretries 超でロックされたユーザのカウンタをリセットする。
業務シナリオ: - ユーザがパスワード忘れて 5 回連続失敗 → アカウントロック → 解除依頼 - 退職予定者の引き継ぎ中の一時ロック解除 - セキュリティ監査ログで意図的ロック解除の記録要件 - 連休明けの大量ロック解除依頼
頻度: 月数件〜十数件、運用担当が日常的にこなす作業。
前提条件¶
- root 権限
- ロックされたユーザ名が判明していること
- 本人確認手順を組織が定めていること(本人確認なし解除は監査リスク)
- 別の root 権限ユーザでアクセス可能(root 自身がロックされた場合は service mode 必要)
手順¶
Step 1: ロック状態の確認¶
コマンド:
# ロック関連属性を確認
lsuser -a unsuccessful_login_count account_locked time_last_login alice
# /etc/security/lastlog の生データ確認
grep -A 5 alice /etc/security/lastlog
期待される出力:
# lsuser -a unsuccessful_login_count account_locked time_last_login alice
alice unsuccessful_login_count=5 account_locked=false time_last_login=1683100000
# grep -A 5 alice /etc/security/lastlog
alice:
time_last_login = 1683100000
tty_last_login = ssh
host_last_login = 192.168.10.5
unsuccessful_login_count = 5
time_last_unsuccessful_login = 1683200000
注意点:
unsuccessful_login_countがユーザの loginretries 値以上ならロック状態。account_locked=trueの場合は別フラグ(admin が明示的にロックした状態)。- ロック原因の切り分け: 失敗カウンタ vs admin ロック vs パスワード期限切れの 3 種を区別。
Step 2: 失敗カウンタのリセット¶
コマンド:
# unsuccessful_login_count を 0 にリセット
chsec -f /etc/security/lastlog -a unsuccessful_login_count=0 -s alice
# 確認
lsuser -a unsuccessful_login_count alice
期待される出力:
注意点:
- これだけでは account_locked=true が残っているとログイン不可。次の step を確認。
Step 3: account_locked フラグの解除¶
コマンド:
# account_locked が true なら false に
chuser account_locked=false alice
# 確認
lsuser -a account_locked alice
期待される出力:
注意点:
account_locked=trueは admin が明示的にロックした状態(mass disable 等)。意図がない場合のみ false に戻す。
Step 4: パスワード期限切れの場合の対処(オプション)¶
コマンド:
# パスワード期限切れか確認
lsuser -a password_changed maxage alice
# pwdadm でパスワード期限を即時失効(次回ログイン時に変更強制)
pwdadm -f ADMCHG alice
# または管理者が新パスワードを設定
passwd alice
pwdadm -f ADMCHG alice
期待される出力:
# lsuser -a password_changed maxage alice
alice password_changed=1672500000 maxage=12
# pwdadm -f ADMCHG alice
(出力なし、成功)
注意点:
maxage=12= 12 週で失効。password_changedから計算して期限切れか判定。- ADMCHG フラグを立てると次回ログイン時に新パスワード入力を要求される。
Step 5: 解除確認¶
コマンド:
# 全関連属性を一括確認
lsuser -a unsuccessful_login_count account_locked time_last_login password_changed alice
# 別端末から alice でログイン試行(運用テスト)
# - 既存パスワードでログイン成功するか
# - ADMCHG 設定済みなら新パスワード変更要求が出るか
期待される出力:
# lsuser -a unsuccessful_login_count account_locked time_last_login password_changed alice
alice unsuccessful_login_count=0 account_locked=false time_last_login=1683100000 password_changed=1683300000
注意点:
- 別端末からの実ログインテストが最終確認。
- 本人にメール等で「ロック解除しました、新パスワードに変更してください」と通知。
検証¶
チェックリスト:
- [ ]
lsuser -a unsuccessful_login_count aliceが 0 - [ ]
lsuser -a account_locked aliceが false - [ ] alice でログイン試行 → 成功する
- [ ] ADMCHG 設定済みの場合、ログイン直後に新パスワード入力を要求
- [ ] 監査ログ(/var/log/secure 等)に解除作業の記録が残る
監査要件対応: - 解除依頼者・承認者・実施者・対象ユーザ・実施日時を記録(運用ログ・チケット) - 重要システムは解除前に本人確認実施(電話・対面)
ロールバック¶
通常 rollback は不要(ロック解除を取り消す = 再ロック)。
意図しない解除または監査要件で再ロックしたい場合:
-
account_locked を再 true 化:
-
失敗カウンタを意図的に上げる:
-
パスワード即時失効:
-
確認:
関連エントリ¶
- 用語: RBAC, user
- コマンド:
lsuser,chsec,chuser,pwdadm,passwd - 設定: /etc/security/lastlog, /etc/security/user, /etc/security/login.cfg
- 関連手順: cfg-user-add, inc-login-locked
典型的な障害パターン¶
症状: 解除直後に再ロックされる
- 原因: アプリが古いパスワードで自動再試行している(cron ジョブ、Web 自動ログイン等)
- 対処:
lastcomm alicelast aliceで誰がアクセスしているか追跡、該当アプリ停止または認証情報更新
症状: chsec で Method error: 0500-008
- 原因: /etc/security/lastlog のパーミッションが壊れている
- 対処:
chmod 600 /etc/security/lastlog、chown root:security /etc/security/lastlog
症状: lsuser で属性表示できるが alice ログインが拒否される
- 原因: PAM/LDAP 統合環境で AIX 側だけでなく LDAP 側のロックが残っている
- 対処: LDAP サーバ側のロック解除(ldapsearch + ldapmodify、または管理 UI)
症状: root 自身がロックされて作業不可
- 原因: root の loginretries 超、または account_locked=true
- 対処: コンソールから service mode で boot → 単一ユーザモードで /etc/security/lastlog 編集
出典: S_AIX73_security
cfg-disk-add: 新規ディスクの認識(cfgmgr)¶
重要度: S 級詳細版 / 用途: ストレージFS
目的¶
SAN/SCSI で割り当てた新規 LUN を AIX に認識させる。
業務シナリオ: - ストレージ管理者から新規 LUN 割り当て後の OS 認識 - 増設したローカル SCSI/SAS ディスクの認識 - DLPAR 後に追加された I/O アダプタの再構成 - MPIO 構成の paths 数増加への対応
前提条件¶
- root 権限
- ストレージ側(SAN)で割り当て・マッピング・LUN masking 完了
- FC スイッチの zoning OK
- 物理 SCSI 接続の場合は配線済
- 必要な fileset インストール済(devices.common.IBM.fc.* 等)
手順¶
Step 1: 現状確認¶
コマンド:
# 現在のディスク数
lspv | wc -l
# 現在のアダプタ
lsdev -Cc adapter | grep -E "fcs|scsi"
# FC アダプタの状態(FC 接続の場合)
lsdev -Cc disk
lsdev -Cc adapter -t pcixchok | head
期待される出力:
# lspv | wc -l
2
# lsdev -Cc adapter | grep -E "fcs|scsi"
fcs0 Available 11-T1 8Gb PCI Express Dual Port FC Adapter
fcs1 Available 11-T2 8Gb PCI Express Dual Port FC Adapter
# lsdev -Cc disk
hdisk0 Available 11-T1-01 MPIO IBM 2076 FC Disk
hdisk1 Available 11-T1-02 MPIO IBM 2076 FC Disk
注意点:
- FC アダプタが Available 状態でないと SAN ディスク認識不可。
- Defined のままなら
cfgmgr -l fcs0で再構成。
Step 2: cfgmgr 実行¶
コマンド:
期待される出力:
# cfgmgr -v
----------------
Calling Configuration Manager
attempting to configure device 'sys0'
attempting to configure device 'sysplanar0'
... 中略 ...
attempting to configure device 'fscsi0'
attempting to configure device 'hdisk2'
Method "/usr/lib/methods/cfgsisscsia -l hdisk2 ..." invoked
attempting to configure device 'hdisk3'
Method "/usr/lib/methods/cfgsisscsia -l hdisk3 ..." invoked
Configuration Manager finished.
# lspv
hdisk0 00f6f5d05a1b2c3d rootvg active
hdisk1 00f6f5d05a1b2c4e rootvg active
hdisk2 none None
hdisk3 none None
注意点:
- cfgmgr 実行に時間かかる場合あり(FC SAN で全パス再スキャン、数十秒〜数分)。
- 新 hdisk が出ない場合: SAN 側 LUN masking、FC zoning、アダプタ Available 状態を再確認。
Step 3: PVID 割り当て¶
コマンド:
期待される出力:
# chdev -l hdisk2 -a pv=yes
hdisk2 changed
# lspv
hdisk0 00f6f5d05a1b2c3d rootvg active
hdisk1 00f6f5d05a1b2c4e rootvg active
hdisk2 00f6f5d05a1b2c5f None
hdisk3 00f6f5d05a1b2c60 None
注意点:
- PVID は VG への組み込み時に必要。new disk なら none → 割り当て。
- 他システムで使われていた PV は要注意。pv=yes ではなく pv=clear で完全クリアが安全。
Step 4: MPIO 属性確認・調整¶
コマンド:
# MPIO 属性の主要 3 つを確認
lsattr -El hdisk2 -a reserve_policy -a algorithm -a queue_depth
# AIX 7.3 既定値を反映(DS8000 の場合)
chdev -l hdisk2 -a reserve_policy=no_reserve -U
chdev -l hdisk2 -a algorithm=shortest_queue -U
chdev -l hdisk2 -a queue_depth=64 -U
# 全 MPIO パス確認
lspath -l hdisk2
期待される出力:
# lsattr -El hdisk2 -a reserve_policy -a algorithm -a queue_depth
reserve_policy no_reserve Reserve Policy True
algorithm shortest_queue Algorithm True
queue_depth 64 Queue DEPTH True
# lspath -l hdisk2
Enabled hdisk2 fscsi0
Enabled hdisk2 fscsi1
Enabled hdisk2 fscsi2
Enabled hdisk2 fscsi3
注意点:
- reserve_policy=no_reserve は HA/LPM 環境必須。SCSI-2 reserve は legacy。
- queue_depth はストレージ仕様により異なる: DS8000=64, SVC/FlashSystem=32。
- lspath で全パスが Enabled でないと冗長性なし。Disabled なら原因調査。
検証¶
チェックリスト:
- [ ]
lspvに新 hdisk が表示 - [ ] 新 hdisk の状態が Available(Defined ではない)
- [ ] PVID が割り当てられている
- [ ]
lsattr -El hdiskNで reserve_policy=no_reserve(PowerHA/LPM 環境必須) - [ ]
lspath -l hdiskNで全パス Enabled(MPIO 環境) - [ ]
bootinfo -s hdiskNでサイズ表示(KB 単位)
追加検証(オプション):
- dd if=/dev/hdiskN of=/dev/null bs=1M count=100 で読み込み速度測定
- iostat で当該 hdisk の活動率確認
ロールバック¶
意図しない認識の場合:
-
当該 hdisk が他用途で使われていないか確認:
-
ODM から削除:
-
確認:
注意: 既に VG に組み込んでいる場合は事前に reducevg で VG から外し、varyoffvg 必要。
関連エントリ¶
- 用語: MPIO, PV, PVID
- コマンド:
cfgmgr,lspv,lsdev,chdev,lsattr,lspath,rmdev - 設定: ODM
- 関連手順: cfg-vg-lv, cfg-mpio-tuning, inc-disk-replace
典型的な障害パターン¶
症状: cfgmgr 実行しても新 hdisk が現れない
- 原因: 1) ストレージ側 LUN masking 未設定、2) FC zoning 不正、3) アダプタ Defined
- 対処: ストレージ管理者に依頼、
fcstat fcs0でアダプタ統計、lsdev -Cc adapter | grep fcs
症状: 新 hdisk は表示されるが状態が Defined
- 原因: デバイスドライバ不足、または config メソッド失敗
- 対処:
mkdev -l hdiskNで個別 config、必要なら追加 fileset インストール
症状: chdev -a pv=yes で 0516-732 chdev: Cannot create PVID
- 原因: PV にロック残骸、または同時アクセスエラー
- 対処: 他プロセスで使用中か確認、再起動後再試行
症状: MPIO で一部パスが Disabled / Failed
- 原因: FC スイッチ片パス障害、またはアダプタ問題
- 対処: errpt で hdisk/fscsi エラー確認、
chpath -l hdiskN -p fscsi0 -s enableで再有効化試行
症状: queue_depth 変更で 0514-040 Error initializing a device
- 原因: デバイスがオープン中、属性変更不可
- 対処:
-Uを-Pに変更(次回 boot 反映)、または unmount 後に再 chdev
出典: S_AIX73_devicemanagement
cfg-mpio-tuning: MPIO 属性のチューニング¶
重要度: A 級詳細版 / 用途: 性能
目的¶
AIX 7.3 で reserve_policy / algorithm / queue_depth の既定値が変更されたため、業務影響に応じて調整する。
業務上のシナリオ: - AIX 7.x からのマイグレ後の MPIO 既定値見直し - HA/LPM 環境で reserve_policy=no_reserve 必須化 - I/O 性能改善のための queue_depth 増加
前提条件¶
- root 権限
- 対象 hdisk が Available 状態
- ストレージ仕様(DS8000 / SVC / FlashSystem 等)の queue_depth 推奨値を IBM ドキュメントで確認
手順¶
Step 1: 現状確認¶
コマンド:
期待される出力:
reserve_policy single_path Reserve Policy True
algorithm round_robin Algorithm True
queue_depth 20 Queue DEPTH True
注意点:
- AIX 7.x マイグレ機では旧既定値(single_path / round_robin / 小 queue_depth)の場合あり。
- AIX 7.3 新規ディスク既定: no_reserve / shortest_queue / 64 (DS8000) or 32 (SVC/Flash)。
Step 2: queue_depth 変更(DS8000 例)¶
コマンド:
期待される出力:
注意点:
- -U で動的反映(オープン中可)。
- ストレージ仕様超過の値はストレージ側でエラー発生の原因。
Step 3: reserve_policy = no_reserve(HA/LPM 必須)¶
コマンド:
期待される出力:
注意点:
- PowerHA/LPM 環境では no_reserve 必須。
- single_path のままだと別ノードからの varyonvg が SCSI reserve で失敗。
Step 4: algorithm = shortest_queue(既定)に戻す¶
コマンド:
期待される出力:
注意点:
- shortest_queue は MPIO 全パス間で動的負荷分散。
Step 5: 確認¶
コマンド:
期待される出力:
reserve_policy no_reserve Reserve Policy True
algorithm shortest_queue Algorithm True
queue_depth 64 Queue DEPTH True
注意点:
- 全 hdisk 一括変更は for ループで
for h in $(lsdev -Cc disk -F name); do chdev -l $h -a queue_depth=64 -U; done。
検証¶
- iostat -DRTl で該当 hdisk のレイテンシ確認
- errpt でディスクエラーが新規発生していない
- アプリ側で I/O 性能改善
ロールバック¶
chdev -l hdisk1 -a queue_depth=20 -U chdev -l hdisk1 -a reserve_policy=single_path -U chdev -l hdisk1 -a algorithm=round_robin -U
関連エントリ¶
- 用語: MPIO, PV, queue_depth, reserve_policy
- コマンド:
lsattr,chdev,lspath,iostat - 設定: queue_depth, reserve_policy, algorithm
- 関連手順: cfg-disk-add, inc-disk-replace
典型的な障害パターン¶
症状: chdev で 0514-040 Error initializing a device
- 原因: デバイスがオープン中で属性変更不可
- 対処: -U が効かない属性は -P で次回 boot 反映、または unmount 後に再 chdev
症状: queue_depth を上げたら storage 側で I/O エラー
- 原因: ストレージ仕様の queue_depth 上限超過
- 対処: ストレージマニュアル確認、適正値に下げる
出典: S_AIX73_devicemanagement
cfg-tcp-buffers: TCP 送受信バッファチューニング¶
重要度: A 級詳細版 / 用途: 性能
目的¶
高遅延 WAN や 10GbE 環境で TCP throughput を上げる。
業務上のシナリオ: - 拠点間 NFS マウントの転送速度改善 - DR サイトへのバックアップデータ転送の最適化 - 10GbE 環境での既定値(256KB)から大バッファ化
前提条件¶
- root 権限
- 業務で TCP throughput が要件になっていること
- アプリ側が setsockopt で個別設定していないこと(している場合は OS 側設定が無視される)
手順¶
Step 1: 現状確認¶
コマンド:
期待される出力:
NAME CUR DEF BOOT MIN MAX UNIT TYPE
DEPENDENCIES
--------------------------------------------------------------------------------
sb_max 1048576 1048576 1048576 4096 ALL byte D
NAME CUR DEF BOOT MIN MAX UNIT TYPE
DEPENDENCIES
--------------------------------------------------------------------------------
tcp_sendspace 262144 262144 262144 4096 ALL byte C
sb_max
NAME CUR DEF BOOT MIN MAX UNIT TYPE
DEPENDENCIES
--------------------------------------------------------------------------------
tcp_recvspace 262144 262144 262144 4096 ALL byte C
sb_max
NAME CUR DEF BOOT MIN MAX UNIT TYPE
DEPENDENCIES
--------------------------------------------------------------------------------
rfc1323 1 0 1 0 1 boolean C
注意点:
- AIX 7.3 既定: sb_max=1MB, tcp_sendspace/recvspace=256KB, rfc1323=1(有効)。
- TYPE=D は dynamic、C は connection(新規接続から有効)。
Step 2: 値を変更(永続)¶
コマンド:
no -p -o sb_max=4194304
no -p -o tcp_sendspace=1048576
no -p -o tcp_recvspace=1048576
no -p -o rfc1323=1
期待される出力:
Setting sb_max to 4194304
Setting sb_max to 4194304 in nextboot file
Setting tcp_sendspace to 1048576
Setting tcp_sendspace to 1048576 in nextboot file
Setting tcp_recvspace to 1048576
Setting tcp_recvspace to 1048576 in nextboot file
Setting rfc1323 to 1
Setting rfc1323 to 1 in nextboot file
注意点:
- sb_max は tcp_sendspace/recvspace の 2 倍以上必要。
- rfc1323=1 で TCP window scaling 有効化(64KB 超バッファ必須)。
- -p で実機 + nextboot 両方に永続保存。
Step 3: 確認¶
コマンド:
期待される出力:
注意点:
- 既存接続には影響しない。アプリ再接続後から有効。
検証¶
- netperf や iperf 等で実 throughput 測定
- netstat -p tcp でウィンドウサイズ確認
- アプリログで socket buffer エラーが出ないこと
ロールバック¶
no -d sb_max no -d tcp_sendspace no -d tcp_recvspace no -d rfc1323
関連エントリ¶
- 用語: TCP/IP, tunable
- コマンド:
no,netstat - 設定: sb_max, tcp_sendspace, tcp_recvspace, rfc1323
- 関連手順: inc-network-down,
cfg-network-services
典型的な障害パターン¶
症状: tcp_sendspace 増加後も throughput が上がらない
- 原因: アプリが setsockopt で SO_SNDBUF を明示設定している
- 対処: アプリのソケット設定確認、netstat -an で実 buffer サイズ確認
症状: メモリ消費が急増
- 原因: 大バッファ × 大量接続
- 対処: sb_max を妥当な範囲に設定、接続数制限
症状: no -p で Restricted tunable エラー
- 原因: AIX 7.3 で restricted 化された tunable
- 対処: -F オプション追加(リスク認識のうえ)
出典: S_AIX73_performance
cfg-ioo-tuning: j2_inodeCacheSize の調整¶
重要度: A 級詳細版 / 用途: 性能
目的¶
AIX 7.3 で既定 200 になった j2_inodeCacheSize を、低メモリ機で多数 open file する場合に増やす。
業務上のシナリオ: - 4GB 以下の小規模機での open file 失敗 - メールサーバ等の小ファイル多数アクセス系 - AIX 5L/6.1 からのマイグレ後の旧既定値(400)に戻す
前提条件¶
- root 権限
- 低メモリ警告(vmstat -v に inode buf extends/lookup increases)が観測される
- 物理メモリの一定割合を inode キャッシュに割く余裕があること
手順¶
Step 1: 現状確認¶
コマンド:
期待される出力:
NAME CUR DEF BOOT MIN MAX UNIT TYPE
DEPENDENCIES
--------------------------------------------------------------------------------
j2_inodeCacheSize 200 200 200 1 1000 numeric D
NAME CUR DEF BOOT MIN MAX UNIT TYPE
DEPENDENCIES
--------------------------------------------------------------------------------
j2_metadataCacheSize 200 200 200 1 1000 numeric D
# vmstat -v | grep -i inode
12345 extends to inode buffers
67890 inode lookup increases
注意点:
- extends/increases が増え続けるなら inode キャッシュ不足。
- AIX 7.3 既定 200 は AIX 7.1 で 400→200 に変更されたもの。
Step 2: 値を 400 に戻す(永続)¶
コマンド:
期待される出力:
Setting j2_inodeCacheSize to 400
Setting j2_inodeCacheSize to 400 in nextboot file
Setting j2_metadataCacheSize to 400
Setting j2_metadataCacheSize to 400 in nextboot file
注意点:
- 通常は inode と metadata を同値で運用。
- TYPE=D は動的、再起動不要。
Step 3: 確認¶
コマンド:
期待される出力:
NAME CUR DEF BOOT MIN MAX UNIT TYPE
DEPENDENCIES
--------------------------------------------------------------------------------
j2_inodeCacheSize 400 200 400 1 1000 numeric D
注意点:
- CUR と BOOT が 400、DEF は変わらず 200。
Step 4: 効果測定¶
コマンド:
期待される出力:
注意点:
- 数分後にカウンタの増加率が下がっていれば効果あり。
- アプリ側で open file 失敗が解消することを確認。
検証¶
- ioo -L で値が反映
- vmstat -v の extends/increases 増加が止まる
- アプリで open file エラーが解消
ロールバック¶
ioo -d j2_inodeCacheSize ioo -d j2_metadataCacheSize
関連エントリ¶
- 用語: VMM, JFS2, ioo
- コマンド:
ioo,vmstat,vmo - 設定: j2_inodeCacheSize, j2_metadataCacheSize
- 関連手順:
cfg-vmo-tuning, inc-perf-degradation
典型的な障害パターン¶
症状: ioo -p で Restricted tunable
- 原因: tunable が restricted 化されている
- 対処: -F オプション追加(リスク認識のうえ)
症状: 値を上げてもメモリ消費が上がらない
- 原因: JFS2 アクセスが少ないアプリ
- 対処: 対象アプリが JFS2 を多用しているか確認、別 tunable(minperm% 等)を見直し
出典: S_AIX73_performance
概念リファレンス(参照 stub - v11 追加)¶
本章本文中で参照される config 概念 26 件の anchor を補完。各 stub は AIX 7.3 公式マニュアルの該当章リンクのみ(詳しい説明は本サイト用語集 03-glossary.md と公式マニュアルを参照)。
TCP/IP¶
Transmission Control Protocol / Internet Protocol。AIX のネットワークスタック基盤。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=communicationsmanagement
用語集も参照: 03-glossary.md
ODM (Object Data Manager)¶
AIX のシステム構成情報を保持するオブジェクト DB(/etc/objrepos 等)。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=object-data-manager
用語集も参照: 03-glossary.md
SRC (System Resource Controller)¶
サブシステム起動・停止・監視を統括する仕組み。lssrc/startsrc/stopsrc で操作。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=system-resource-controller
用語集も参照: 03-glossary.md
syslogd¶
AIX 標準のシステムロギングデーモン。/etc/syslog.conf で出力先制御。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=syslogd-daemon
用語集も参照: 03-glossary.md
errlog (Error Log)¶
AIX カーネル / ハードウェア / ソフト障害を記録するバイナリログ(errpt で表示)。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=errlog-error-logging
用語集も参照: 03-glossary.md
errnotify¶
errlog エントリ発生時に自動アクション(メール送信・スクリプト実行等)を起動する ODM 機構。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=errnotify-object-class
用語集も参照: 03-glossary.md
BIND 9.18¶
AIX 7.3 TL3 で標準の DNS サーバ実装バージョン。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=configuring-bind
用語集も参照: 03-glossary.md
NFS (Network File System)¶
ネットワークファイルシステム。AIX は NFSv3 / v4 をサポート。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=nfs-network-file-system
用語集も参照: 03-glossary.md
LVM (Logical Volume Manager)¶
AIX のストレージ抽象化層。VG → LV → FS の階層管理。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=logical-volume-manager
用語集も参照: 03-glossary.md
VG (Volume Group)¶
PV を束ねる論理単位。rootvg / datavg 等。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=volume-groups
用語集も参照: 03-glossary.md
LV (Logical Volume)¶
VG 内に切り出される論理ボリューム。FS や raw データ用に使用。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=logical-volumes
用語集も参照: 03-glossary.md
PV (Physical Volume)¶
LVM 配下の物理ディスク。hdisk0 等。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=physical-volumes
用語集も参照: 03-glossary.md
PVID (PV Identifier)¶
PV を一意識別する 16 桁 ID。lspv で確認可能。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=physical-volumes
用語集も参照: 03-glossary.md
JFS2¶
AIX 標準のジャーナリング FS(Enhanced Journaled File System)。LVM 上に作成。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=journaled-file-system-jfs2
用語集も参照: 03-glossary.md
BLV (Boot Logical Volume)¶
起動用 LV(hd5 等)。bosboot で再構築。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=boot-logical-volume
用語集も参照: 03-glossary.md
PP (Physical Partition)¶
PV を分割した最小割当単位。VG 作成時の PP サイズで決定。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=physical-partitions
用語集も参照: 03-glossary.md
MPIO (Multi-Path I/O)¶
AIX 標準のマルチパス I/O 機構。複数 FC/SAS 経路の冗長化。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=multi-path-i-o-mpio
用語集も参照: 03-glossary.md
RBAC (Role-Based Access Control)¶
AIX 6.1 以降の役割ベース権限管理。Domain RBAC を含む。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=role-based-access-control-rbac
用語集も参照: 03-glossary.md
fileset¶
SMP/E でいう PTF 単位相当。bff パッケージの最小インストール単位(例: bos.rte.libc)。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=filesets-installed-software
用語集も参照: 03-glossary.md
LPP (Licensed Program Product)¶
fileset 群の上位束。例: openssh.base.server。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=licensed-program-products
用語集も参照: 03-glossary.md
VRMF (Version.Release.Modification.Fix)¶
AIX fileset のバージョン表記(例: 7.3.3.0)。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=filesets-installed-software
用語集も参照: 03-glossary.md
TL (Technology Level)¶
AIX のメジャー機能パッケージ。例: AIX 7.3 TL3。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=service-strategy
用語集も参照: 03-glossary.md
SP (Service Pack)¶
TL に対する保守パッケージ。例: AIX 7.3 TL3 SP1。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=service-strategy
用語集も参照: 03-glossary.md
NIM (Network Installation Management)¶
AIX のネットワーク経由集中インストール / 保守機構。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=network-installation-management-nim
用語集も参照: 03-glossary.md
VMM (Virtual Memory Manager)¶
AIX 仮想記憶管理サブシステム。vmo で tunable 制御。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=virtual-memory-manager
用語集も参照: 03-glossary.md
kdb¶
カーネルデバッガ。crash dump / 稼働中カーネルを解析する対話ツール。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=k-kdb-command
用語集も参照: 03-glossary.md
VMM tuning 参照(v11 追加 stub)¶
VMM の tunable(minperm / maxperm / minfree / maxfree / lru_file_repage 等)の調整手順は本サイトでは 02. 設定値一覧 の v10 補足セクション「環境依存 tunable」で扱います。具体的な vmo / ioo コマンドは 01-commands.md#vmo と 01-commands.md#ioo を参照。
公式マニュアル: https://www.ibm.com/docs/en/aix/7.3?topic=v-vmo-command